まもなく17周年を迎えるpixivでは、長年にわたり作品などの全文検索基盤としてApache Solrを使用してきました。
しかし、サービスの規模が拡大する中で、従来の基盤に問題が生じていました。これを受けて、pixivでは全文検索基盤のリプレイスを実行しました。
今回のリプレイスにより、pixivでは検索結果の更新反映時間や検索APIのレイテンシが大幅に短縮されました。また、今後のスケールに対応可能になり、新機能開発においても全文検索が容易に利用できるようになりました。
本記事では、pixivの全文検索基盤の歴史や、今回オンプレミス環境でElasticsearchクラスタを構築し、リプレイスを完了するまでの取り組みについてご紹介します。
こんにちは。pixivのnamazuです。最近、私たちのチームで進めていたpixivの全文検索基盤のリプレイスが完了しました。この機会に、pixivの全文検索基盤の歴史などを交えながら、取り組みについてお伝えできればと思います。
なお始めに断りをいれさせてください。
- 既存の仕組みがこれまでpixivを支えてくれたこと、そしてそれに関わったすべての方々に深い敬意を抱いています。
- 今記事では、SolrとElasticsearchの優劣について触れる意図はありません。pixivがSolrの運用に課題を抱えていたのは、長期間にわたってSolrの更新やアーキテクチャの見直しを行わなかったことが主な原因です。
pixivの全文検索基盤の用途とその歴史
最初にpixivにおける全文検索基盤の用途とその歴史について説明します。
pixivでは、ユーザーが作品としてイラスト、マンガ、小説を投稿できます。これらの作品には、タイトルやキャプション、タグなど、さまざまな情報が付けられています。ユーザーは、これらの情報に基づいて検索ページで好みの内容を検索できます。また、AND、OR、NOTといった演算子を用いた複雑な条件設定や、特定の語句を除外するマイナス検索も可能です。
pixivで作品を検索する方法を知りたい – pixivヘルプセンター
このような検索ページでの絞り込みは、全文検索基盤が利用される典型例です。
さらに、全文検索基盤はpixivにおいて特定の条件に合致する作品を高速に抽出する能力を持っているため、単なる検索ページの機能を実現するだけでなく、さまざまな用途で広く活用されています。例えば、レコメンド機能の裏側を支えたり、そもそも全文検索基盤の絞り込み機能を前提として動作するpixiv関連サービスも存在します。
このように、pixivにおける全文検索基盤は随所で利用されており、不可欠な要素の一つです。参考までに、クエリ数はピーク時に約4k req/s程度に達します。
一般的に、全文検索基盤はサービスの初期から何らかの形で必要とされる事が多いと思います。pixivでも最初期から運用が行われてきました。
pixivの全文検索基盤は以下のような流れで変化しています。
- 2007年9月10日 pixivリリース (検索は必要に応じてMySQLのLIKEで実現 )
- 2007年12月頃 MySQL Tritton (senna)を利用した初代全文検索基盤の完成
- 2011年頃 スケールの問題によりApache Solrを用いてリプレイス
- (この間12年ほど) 検索の絞り込み条件を追加などのその都度の対応や保守
- 2024年4月~ Elasticsearchへの移行PJ本格稼働 ( 今回の主題 )
- 2024年8月末 Elasticsearch移行PJ完了、Solr運用終了
③で構築されたSolrの全文検索基盤が、pixivを長期間にわたって支えてくれたことが分かります。
本題であるElasticsearchへの移行について話す前に、まずはこのSolrの構成と、その際に直面した課題について説明します。
Apache Solrによる全文検索基盤のインフラ構成(2024年の最終構成)は、大まかに以下のようになります。
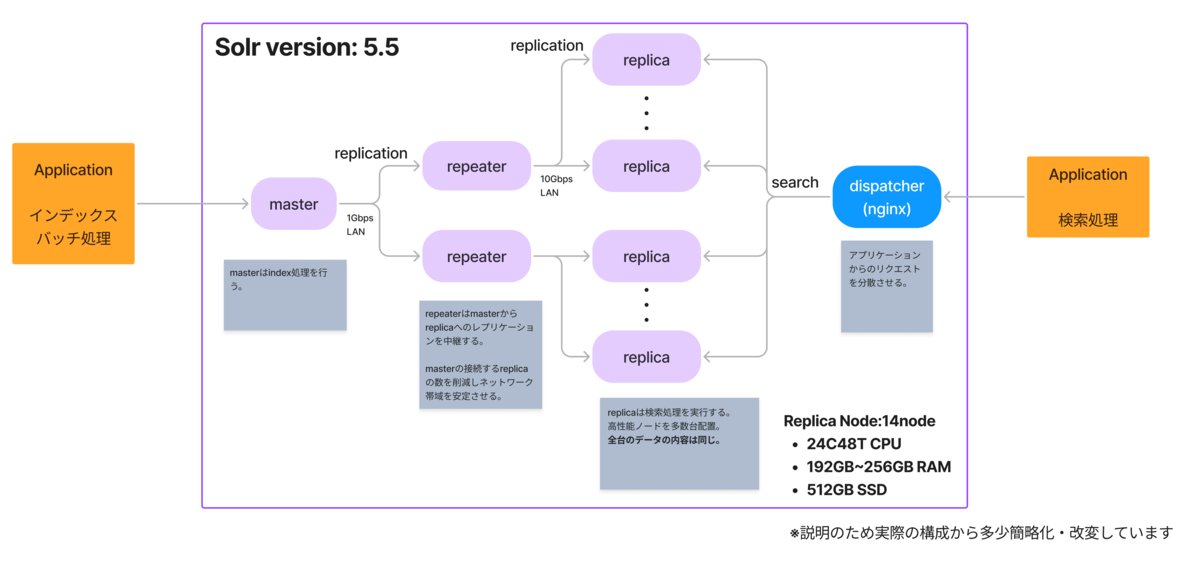
アプリケーションは、masterノードに対してインデックス処理をリクエストします。masterノードがインデックス処理を担当し、帯域の安定化のために通過させているrepeaterノードを介してデータをレプリケートします。一方、アプリケーションはdispatcherを介してオンライン検索を実行し、各replicaノードで分散して処理が行われます。
また、pixivのイラストなどのリソースは、以下のような形でシャーディングしてSolr上で取り扱っています。
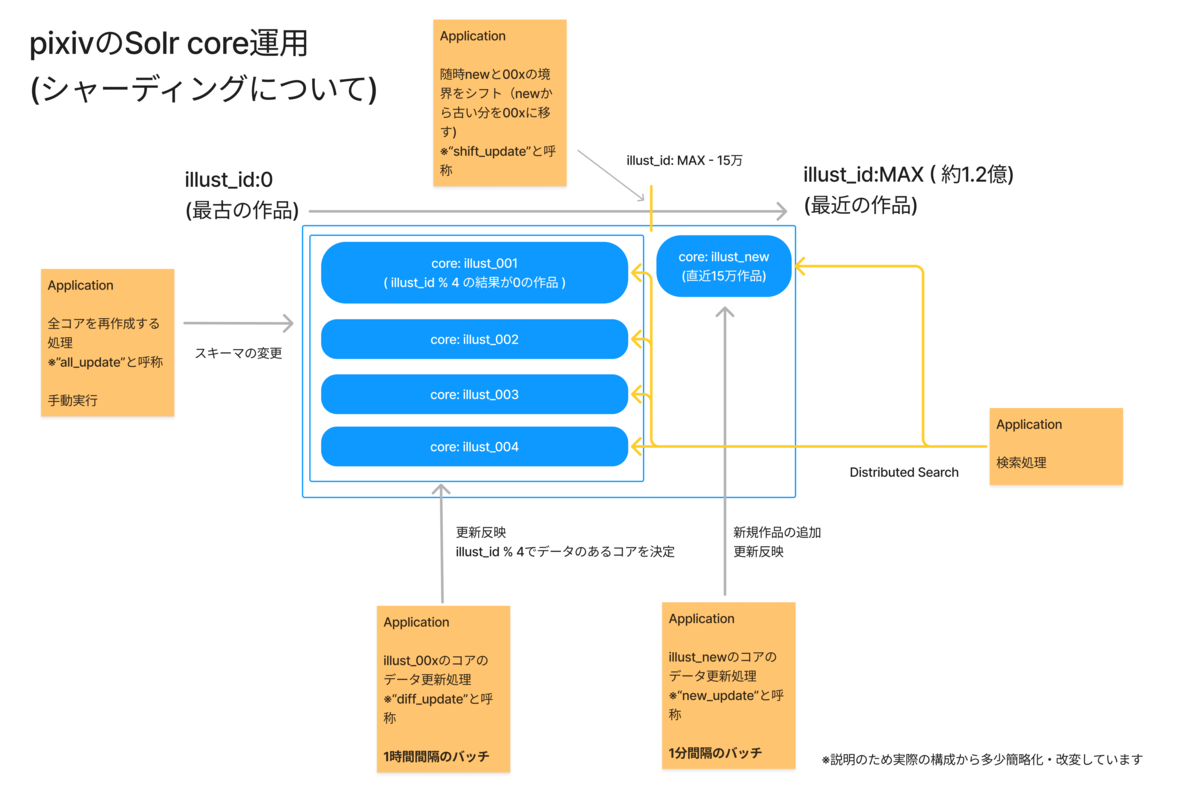
Solrを構築した当時は、Solr Cloud(Solrの構成の一つ)が存在していなかったため、独自にシャーディングを行い、DistributedSearchを利用しました。
イラストなどのデータは、Solr上では主に「new」と呼ばれる1つのコア(インデックス)と、「00x」のように番号が振られた複数のコアで構成されています。newには直近の作品が入り、00xにはそれ以外の作品が格納されます。00xの各番号は、作品のIDをコアの数で割った際の余剰で決定されます。
newコアは高頻度のバッチ処理で更新され、一方の00xコアは1時間ごとのバッチ処理で更新されます。newコアに新規作品を追加し続けると、newが大きくなってしまうため、定期的にnew内の古い作品を00xコアに移す処理も行われます。
この仕組みにより、pixivに投稿された作品は比較的早く検索結果に反映され、またシャーディングによって、作品の増加に対応して検索処理をスケールさせることが可能となっています。
pixivの全文検索基盤の問題
さて、この全文検索基盤はサービス規模の拡大に伴い、以下のような問題に直面することになりました。
masterのインデックスが処理スケールしない問題 : masterノードがシングルノードでインデックス処理を行うため、スループットがmasterノード単一の性能に依存します。しかし、データの増加により、要求がスループットの上限を超えることが発生するようになりました。
replicaの検索負荷増加問題: 検索量が増加したため、より多くのreplicaで参照負荷を分散しないと処理が追いつかなくなりました。全てのreplicaが同一のデータを持ち、偏りがないため、全台で十分なメモリを搭載しないと安定しません。
all_update処理による障害の発生: 上記の2つの問題から、スキーマの変更などで行う「all_update」と社内で呼称するインデックスの再構築処理に非常に時間がかかるようになりました。さらに、実行中は随時行っている更新処理が遅延するなどの問題も発生します。これまでのインデックスから新しいインデックスに参照を切り替えるタイミングでは、キャッシュの関係などから検索リクエストを捌ききれず、一時的な障害が発生することもありました。その結果、all_updateは極力避けるべきオペレーションとなり、実施を回避する形で開発が行われるようになりました。
これらの問題に対処するため、サーバのLANを1Gbpsから10Gbpsに強化したり、メモリを増設したりすることで、何とか凌いできました。
その他、そこまで大きな問題ではないにせよ、解決したい点もいくつか出てきました。
SPOF(Single Point of Failure)の存在:構成上、masterノードを始めとするさまざまなSPOFが存在します。これらの箇所については基本的に自動復旧ができず(自働化のための開発がされていないため)、復旧にはインフラ部のオンコールによる即時対応が必要です。
シャーディングの複雑さ: 独自のシャーディングのため、アプリケーションでは各種バッチ処理を用意し、それを運用する必要があります。また、リシャーディングに関しては大変さの点から実現性に課題がありました。
バージョンの古さ:OSを含め、手が加えられておらず、かなりバージョンが古い状態になっていました。
問題の深刻化、OpenSearchの試みと撤退、そして次の準備
さて、Solrの全文検索基盤が単一のmasterノードでインデックス処理を行うために負荷が分散できないという問題は、2021年ごろに長文を取り扱う「小説本文のインデックス処理」で顕在化しました。
pixivの小説は長い本文を持っていますが、その内容に基づいて検索が可能です。しかし、小説の規模が増加するに伴い、処理しなければならない文章量が増加し、インデックス処理が限界に達することで、検索結果への反映が遅延する事態が発生しました。これは大きな問題です。この状況では、新しい検索フィールドやコアを追加することはさらに困難になります。
プロダクト開発では、随時機能を拡充しながら検索機能も改善したいところですが、この問題がそれを妨げてしまいました。
解決策を見つけるための検討が行われました。私は直接的には関わっていませんが、最初の候補として挙がったのは、AWSのOpenSearchへの移行でした。OpenSearchはSolrと同様にApache Luceneを基盤としているため、比較的容易に移行でき、差異も少ないと考えられます。また、クラウドリソースを活用し、ある程度の運用を委譲することで、物理サーバの調達や運用体制の確立にかかる時間を短縮できる点も魅力でした。
しかし、検証の結果、OpenSearchにpixivの全文検索基盤を載せ替えることは見送られることになりました。その理由は機能的な問題ではなく、費用面での問題です。
pixivはオンプレミス環境を保有しており、必要となるリソースが大きく、またそのリソースの需要に大きな変動がないため、オンプレミスで長期間にわたり安定運用することでコストを削減しています。
マネージドサービスの完成度の高さやオンプレミス運用に関わるチームのコストなど単なるサーバ費用以外にも考慮するべき点はありますが、pixivの検索全体という大規模なストレージや計算リソースをクラウドで確保するのと、オンプレミスで確保するのとでは、5年、10年という長期的な視点で見ると、サーバのランニングコストに大きな差が生じることが判明しました。
OpenSearchで全文検索基盤を実現する場合、当時算出された費用は、長期的な運用を考えると事業上難しいものでした。
この結果、全文検索基盤をオンプレミスでどうにかする方向に決定しました。これは2022年中頃から年末にかけての出来事です。
さて、オンプレミスでなんとかすると言っても、pixivの検索基盤を載せ替える規模のサーバがデータセンターに余っているわけではありません。pixivのSolrのreplicaは不安定であったために追加を続けた結果、1台あたりCPUが24コア48スレッド、RAMが192〜256GB程度のサーバが約14台で構成されています。仮に半分から始めるとしても、少なくとも7台は必要です。しかし、そのようなサーバは余っていなかったため、まずはサーバの調達から始めることになりました。
メモリの追加やLAN帯域の増強、アプリケーションの改善、ノード自体の追加によって、当時の問題はある程度抑えられていたため、急ぐ必要はなく、2023年はこのサーバの調達・キッティング・ラッキングを進めることになりました。
Elasticsearchへ
2024年4月、サーバも揃い、稼働できる状態になったので(その前はPHPとOSの更新を行っていました)、全文検索基盤の再構築が始まりました。
当時、サーバは既に用意されていましたが、具体的な設計はあまり決まっていませんでした。主な要求は以下の通りです。
- ある程度のベアメタルサーバを用意したので、それを使って全文検索基盤を構築したい。
- 次のピークであるお盆頃までには完了させたい。つまり4ヶ月で行いたい。
- 少なくとも検索反映時間を短縮したい。また、プロダクトの要求に応じて、新しいフィールドを容易に追加したり、検索できる項目を増やせるようにしたい。
- 可用性が高く、保守運用が楽なものにしたい。サーバ故障時にインフラ部の即時対応を必要としないようにしたい。
これらの要件を踏まえ、まずはミドルウェアとして何を使うかから検討が始まりました。
結論として、Elasticsearchで構築を進めることになりました。主にSolr(Solr Cloud構成)との比較が行われましたが、インフラ部では既にBOOTHやpixivコミックなどでオンプレミスのElasticsearchクラスタを運用している実績があったため、pixivもElasticsearchを採用することで、オンプレミス環境をElasticsearchに統一できることが期待されました。これにより、規模の経済を活かし、全体的な品質の向上と運用の容易化も同時に狙えると考えました。
Elasticsearchへの移行が難航する可能性もありましたが、ElasticsearchはSolrと同じくApache Luceneを基盤としており、過去にOpenSearchで行った検証の実績から、移行は現実的だろうと判断しました。トークナイザや各種前処理の違いによって、ElasticsearchとSolrでインデックス内容がずれ、体験差異が深刻化する懸念もありましたが、pixivでは主にn-gramが使用されているため、問題が表面化することは少ないだろうと考えました。最悪の場合でも、n-gramの差異に影響を与えるnormalizerなどを自分で実装することで回避できると判断しました。
また、Solrを採用した場合でも、現行のバージョン5.5から9への一気にバージョンアップが必要になるため、前後比較の工数は大して削減されないだろうという結論に至りました。
移行計画の作成
プロジェクトに際して、Elasticsearchへの移行計画を作成しました。問題が発覚した際に切り戻せないリスクを避けるため、また移行時の検索体験の差異が少ないことを立証できるよう、以下のステップを設定しました。
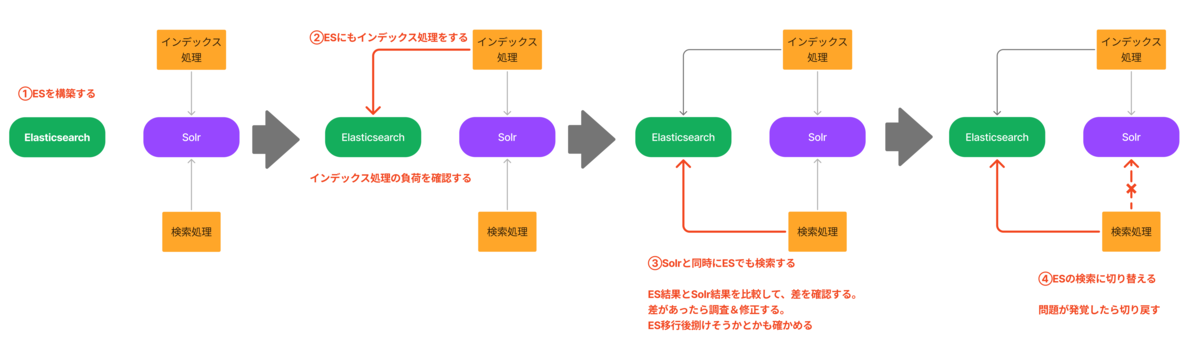
- Elasticsearchクラスタを構築する。
- ElasticsearchにSolrと同等のインデックスを作成し、Solrに加えてElasticsearchにも定期的な更新処理を適用する。 また、更新処理の負荷検証を行う。
- pixivでの検索時にSolrとElasticsearch両方にクエリを送る。 ユーザー向けには引き続きSolrの結果を使用するが、裏側でElasticsearchの結果件数と照合し、差異を確認する。差異が生じた場合は調査し、対処する。さらに、このリクエストを受けているElasticsearchクラスタに対して、ノードの隔離・投入、設定変更など日々発生する作業を試験的に実施し、挙動を確認する。Datadogのダッシュボードや監視用のMonitorといった運用に必要な環境を整備する。また、ハードウェア障害を模したシナリオをテストし、可用性を確認する。想定されるクエリがすべて流れている一定期間の状況を観察し、リクエストが捌ききれるか確認する。
- 移行の懸念点が払拭できたら、pixivからの検索時にユーザー向けにElasticsearchの結果を使用するよう、A/Bテストの仕組みを用いて段階的に切り替える。 問題が発生した場合は、Solrに切り戻して修正を行う。
- ②〜④の流れを、検索基盤で扱うすべてのインデックス(イラスト・小説・ユーザ・グループ・百科事典など)に対して行う。
- Elasticsearchへの移行が完全に完了した後、Solrへのデータ更新・検索クエリを停止する。
- Solrへのデータ更新処理やクエリ生成処理などをコードから削除し、Solrサーバを停止する。
この計画では、最終ステップである⑦番までSolrに対してデータの更新を続けるため、いつでもSolrへの切り戻しが可能です。また、③番の段階における検証作業によって、効果的に差異を検出することができます。
今回、pixivのSolr検索と同等のElasticsearchインデックスを作成し、クエリを完全にミスなく構築することは難しいと予想していました。そのため、何らかの漏れやミスが発生することを前提として計画を進め、最終的にはユーザーリクエストを通じて前後の振る舞いの差異を検出・修正することで、効果的に問題点を発見し、漏れがなくなっていることを立証できるようにしています。
実際、このアプローチにより、検証段階で多数のプログラムのバグや設定ミスを発見・修正することができ、効率的かつ効果的に移行作業を進めることができました。
インフラ構成
今回構築したElasticsearchの構成は、以下のような形としました。
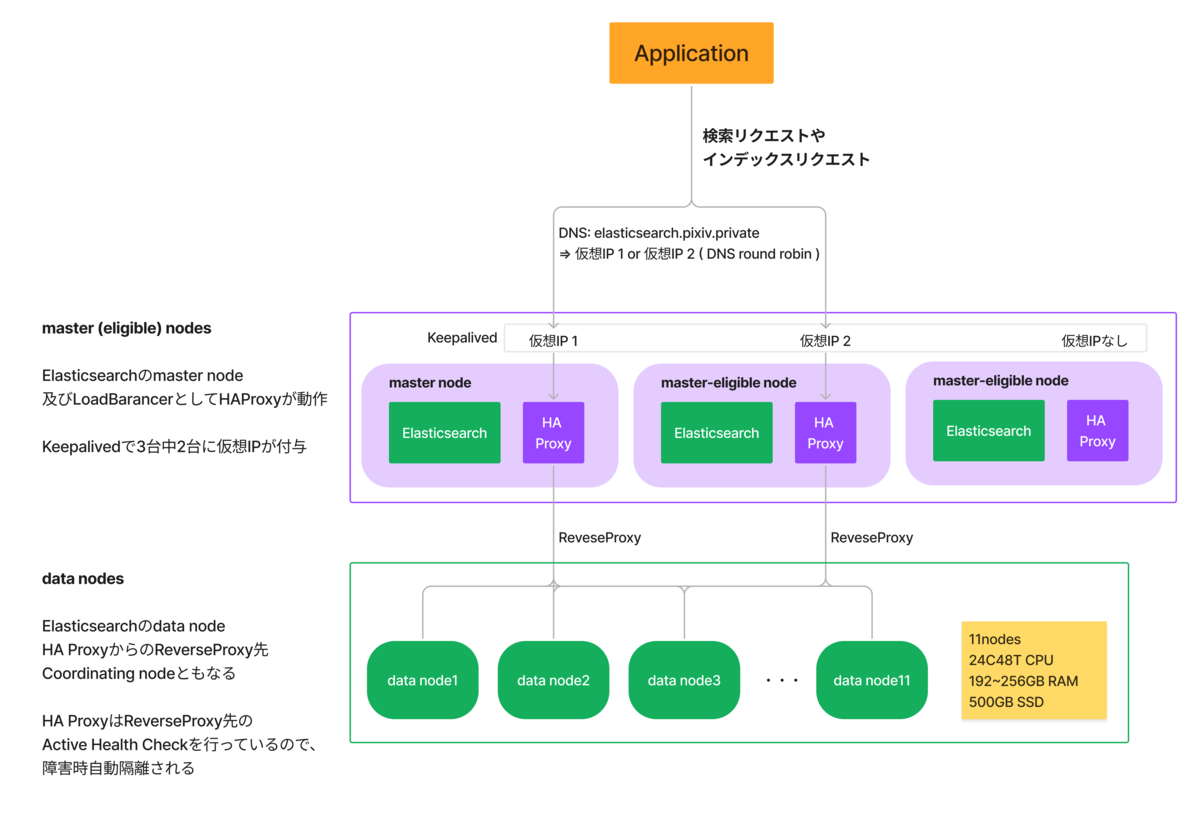
全体として、Elasticsearchクラスタはmaster eligible nodeが3ノード、data nodeが11ノードで構成されています。
アプリケーションがElasticsearchのAPIにアクセスする際には、HAProxyをロードバランサーとして間に挟んでいます。
HAProxyはmasterノードに同居させており、3台のうち2台にKeepalivedで付与される仮想IPを介してアプリケーションから接続されています。HAProxyの負荷は高くないのですが、今回は構造上、1ノードへの集約を避けたかったため、2ノードに仮想IPを付与し、DNSラウンドロビンでアプリケーションからのリクエストが分散するように設定しています。ロードバランサを分散するメリットに対して、障害率の上昇や複雑性の増加がどの程度見合うかは微妙なところなので、将来的には集約させるかもしれません。
HAProxyはdataノードのElasticsearchに接続しています。アクティブヘルスチェックを行っており、ノードに障害が発生した際には自動で隔離されるようになっています。
なお、Elasticsearchに投入されるデータはすべてMySQLに元データが存在するため、現状ではバックアップは行っていません。万が一の破損時には、インデックスを再構築して復旧する予定です。
移行中に発覚した問題と対処
ここからは、移行中にpixivで発覚した問題とその対処について触れます。多くの問題は、ユーザリクエストを用いたSolrとElasticsearchの差分の動的検証の中で発覚し、対処することができました。そのため、ユーザへの影響を抑えた形で問題を把握し、解決することができました。
max_result_windowの調整
Elasticsearchのmax_result_windowの値に起因して、検索ページが特定ページ以上開けないという問題が発生しました。pixivでは、現在プレミアムアカウントを持つユーザーは、検索ページを最大5000ページまで辿ることができます。
max_result_windowの値を大きくすることで、クラスタが不安定になったり、クエリが終わらないのではないかという懸念がありましたが、設定を変更して様子を見たところ、pixivの環境では特段問題は発生しませんでした。そのため、検索ページで表示する件数に合わせてmax_result_windowの値を増加させました。
position_increment_gapの調整
position_increment_gapはインデックスにおいて、配列のように複数の要素を持つプロパティの各要素間の隙間を調整するパラメータですが、これが既存のSolrとの差異を生む原因となりました。
position_increment_gap | Elasticsearch Guide [8.15] | Elastic
pixivでは、次のようなケースでこの差異が発覚し、一部のフィールドにおいてこの値を0に明示的に設定する必要がありました。たとえば、ある作品に「A」と「B」という2つのタグが付いているとします。このとき、pixivのタグ部分一致検索で「AB」と検索すると、「A」と「B」のタグを持った作品が検索結果に表示されるという挙動がありました。
この挙動は、pixivで明示された検索仕様ではなく、タグの検索という文脈では一見不思議に思えるかもしれませんが、社内でヒアリングしたところ、この機能を意図して利用しているケースがあったため、今回はこの挙動を維持することを決めました。
SolrのqとElasticsearchのquery_stringの取り扱い
pixivでは、OR、AND、NOTや括弧を用いた検索クエリが利用できますが、これまではユーザーが入力したクエリをアプリケーション側で最低限のエスケープ処理を行ったうえで、Solrのqパラメータにそのまま入力していました。
今回、Elasticsearchに移行する際、既存コードからの移行のしやすさを考慮して、主にElasticsearchのquery_stringを使用しました。しかし、ElasticsearchとSolrの間で一部のクエリの解釈が異なることが判明しました。これに対処するため、Elasticsearchにクエリを渡す際には、ユーザー入力クエリを構文解析し、フレーズの取り扱いなどを適切に考慮したうえで、query_stringに渡す文字列を生成することになりました。
icu_normalizerの挙動
既存のSolrでも文字の正規化を行っていたため、Elasticsearchでもicu_normalizerを用いてnfkc_cf形式で正規化を行いました。移行当初から何らかの差が出るだろうと予測していましたが、実際にはいくつかのケースで致命的な影響が発生し、対処が必要となりました。
特にpixivで影響が大きかったのは、2点リーダーや3点リーダーの取り扱いです。これらは正規化されると複数のピリオドに変換されますが、pixivではピリオドがタグなどで特別な意味を持つことがあり、ピリオドを用いた検索時に混同を避ける必要がありました。
まず、icu_normalizerのunicode_set_filterオプションを用いて、特定の文字の正規化を回避することを検討しました。しかし、このオプションを適用したところ、絵文字のみで構成された長文の小説に対するインデックス処理が終了しない問題が発覚し、この方法は断念しました。
短時間で原因を特定するのが難しかったため、最終的には前段でchar_filterのmappingを使用し、3点リーダーなど正規化を避けたい文字をUnicodeの私用領域のバイト列に置き換えることで、一時的に対処しました。
移行してみて
さて、様々な課題がありましたが、この移行プロジェクトは8月23日にSolrサーバを全台シャットダウンした事を以て完了しました。ここでは、全文検索基盤のリプレイスによる結果について触れます。
検索結果反映速度が向上
検索結果への反映速度が大幅に向上しました。これまでは、直近に投稿された作品については比較的早く数分以内に検索に反映されていましたが、すべての作品を対象とすると、タグを付けてから検索結果に表示されるまでに1時間程度かかることがありました。
今回の再構築に合わせてインデックス処理を見直したことで、イラストや小説がタグ付けなどの変更を行ってから、検索結果に反映されるまでの時間を30秒以内に短縮することができました。
これにより、作品を編集後、検索結果に素早く反映されるようになり、ユーザーがより早く好みの作品に出会いやすくなったと考えています。また、「検索結果への反映が遅い」というご意見も頂いていたため、これらに応えることができました。
各要素の検索結果への反映時間は、定期的にバッチで測定し、Datadogにカスタムメトリクスとして送信して監視しています。
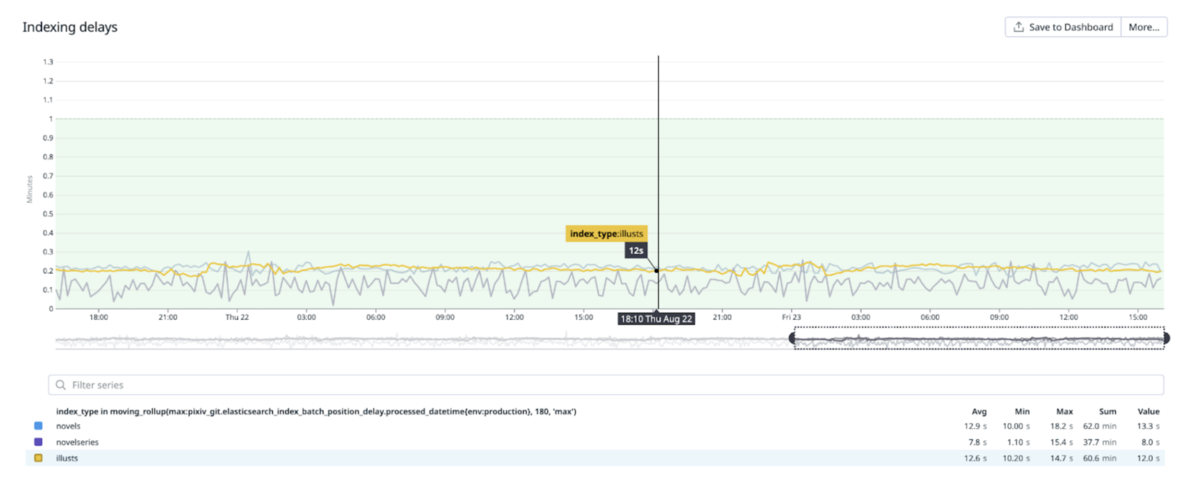
検索APIを始めとするSolrに依存していたエンドポイントでレイテンシが改善
元々の検索基盤が不安定だったため、pixivの検索APIのレイテンシが不安定でした。今回の移行によって、このレイテンシを安定させることができ、特に複雑な検索におけるレイテンシを大幅に削減することができました。
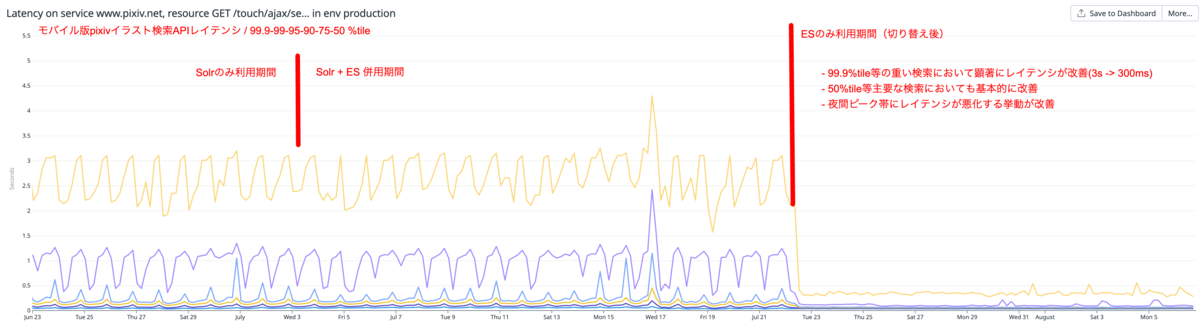
グラフは、モバイル版pixivが利用するイラスト検索APIのレイテンシを示したものです(上位から99.9%、99%、95%、90%、75%、50%タイル)。特に重い検索に該当する99%タイルなどにおいて、レイテンシが顕著に改善したことがわかります。このAPIは、秒間100リクエストを超える頻度で利用されているため、恒常的に発生していた重い検索のレイテンシを大幅に改善できたと言えます。
また、これまで検索APIはSolrが不安定な際にエラーを返すことがありましたが、移行後はエラー数も減少しています。
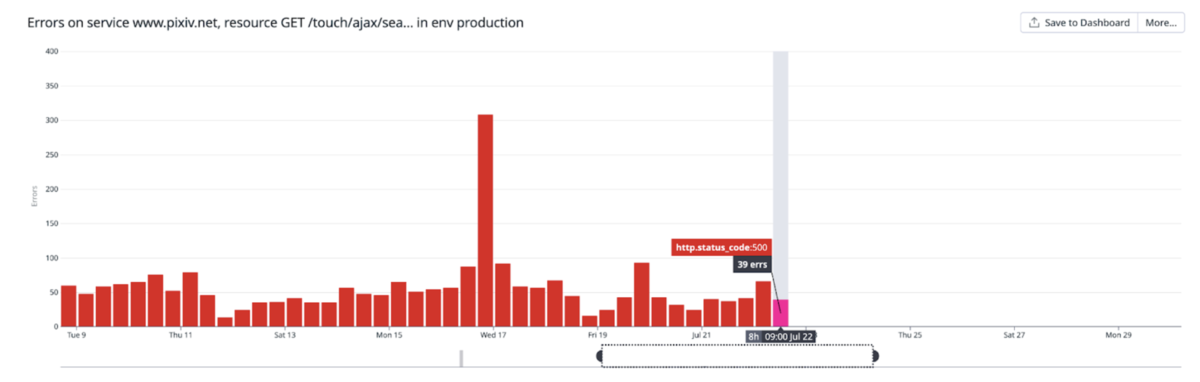
重い検索リクエストの多くは、ORやマイナス検索を多数組み合わせたユーザーの好みに応じたものが多いため、これによりユーザーが自分の好きな作品をより快適に探すことができるようになったと言えるでしょう。
保守運用が容易に
今回の構成では、ノードが2台故障してもクラスタの可用性を維持できるようになったため、システムの可用性が向上しましたが、インフラ部の保守運用面でも大きな改善ができました。
これまでは、深夜や休日を問わず発生するディスク故障などによるノード故障に対して、自動化が十分ではなかったため、オンコール体制に基づく即時対応が必要でした。しかし、今回の構成変更により、これらの対応を翌営業日まで延期することが可能になりました。
これにより、オンコールによる深夜・休日対応を減らすという点で、一歩前進できたと言えます。
新検索基盤のこれから
今回構築した構成はまだ運用を開始して間もないため、さまざまな点で未熟な部分があります。こうした点については、運用を続けながら進化させていきたいと考えています。
例えば、オンプレミスのベアメタル環境では、使用するパーツの性能に大きく依存する部分があります。今回の場合ディスク周りについては、改善の余地があると考えています。現状は安価なSATA SSDを使用していますが、データセンター向けのDWPD3程度あるNVMe SSDなどに切り替えることで、より安定し、リクエスト処理能力の高いクラスタにできると見込んでいます。こうした点については、今後数年の運用状況を見ながら調整していきたいと思います。
また、Elasticsearch自体の課題ではありませんが、検索インデックスの差分更新については、現状MySQLのトリガーを用いてデータ変更を検出しています。現行のpixivのMySQL構成では、ステートメントベースのバイナリログを使用する必要があり、廃止が予告されているため対応が必要です。今後は、アプリケーション側で検索インデックスの差分更新に関するリアーキテクチャに取り組む必要があります。
課題は多く残っていますが、今回の変更により、プロダクトとして全文検索をより柔軟に活用できるようになったため、今後のpixivのさまざまな施策にこの改善を活かしていきたいと考えています。
おわりに
長い記事となりましたが、ご一読いただきありがとうございました。
また、本件に関して、pixivのアプリケーションプログラムのコーディングでも挑戦的なリアーキテクチャに取り組んでおり、私に加えて本件に取り組んでいたpicopicoより、別途Inside記事にて詳しく触れさせていただく予定です。そちらも楽しみにしていただければ幸いです。