

はじめに
こんにちは、インフラ部のsue445です。
ピクシブでは2023年末に自社のデータセンターとAWSとをDirect Connect Gatewayで、データセンターとGoogle CloudとをCloud Interconnectで、それぞれインターコネクト(閉域網接続)を開通しました。
現在PastelaではDirect Connect Gatewayを、pixivcobanではCloud Interconnectをそれぞれ利用してオンプレミスのデータセンターと閉域網接続を行っています。
皆さんの会社でもデータセンターと各クラウドとを専用線などで閉域網接続は行っているかもしれません。しかし複数クラウドでの開通というのはあまり無い事例だと思います。
このエントリでは複数クラウドでの閉域網接続を通して得られた知見や、AWSとGoogle Cloudの微妙な仕様の違いを紹介させていただきます。
FAQ
Q. なぜ同時に開通したのか
Pastelaとpixivcobanのチームからそれぞれアーキテクチャの相談がきた時に、両方ともリリース予定日が近かったので同時に開通作業を行いました。
Q. なぜAWSとGoogle Cloudをそれぞれ採用したのか?
各サービスの特性や各サービスにいるエンジニアの意思などを諸々勘案した結果、冒頭のようなクラウド選択になりました。
ピクシブではAWSとGoogle Cloudを同じくらいの割合で利用しています。
AWSとGoogle Cloudを両方を比較検討した結果、AWSだと技術的な理由によりサービスのやりたいことが実現不可能だったり、Google Cloudに比べて明らかに不利*1ということになればGoogle Cloudを採用します。(もちろんAWSだと実現できてGoogle Cloudだと実現できないこともあります)
しかし、AWSとGoogle Cloudのどちらを利用してもサービスのやりたいことが実現できる場合には各サービスにいるエンジニアのスキルセットやモチベーションを考慮して決定しています。
詳しくはPIXIV MEETUP 2023 の発表資料をご参照ください。
https://speakerdeck.com/sue445/pixiv-cloud-journey?slide=23
インターコネクトの構成図
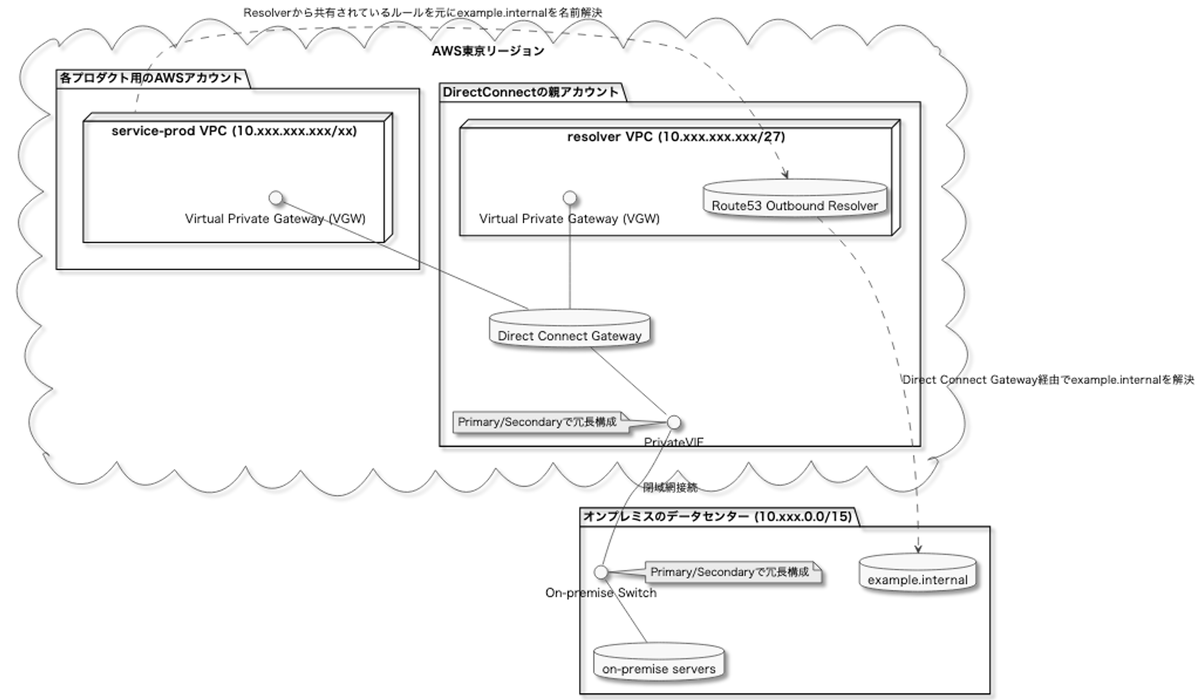
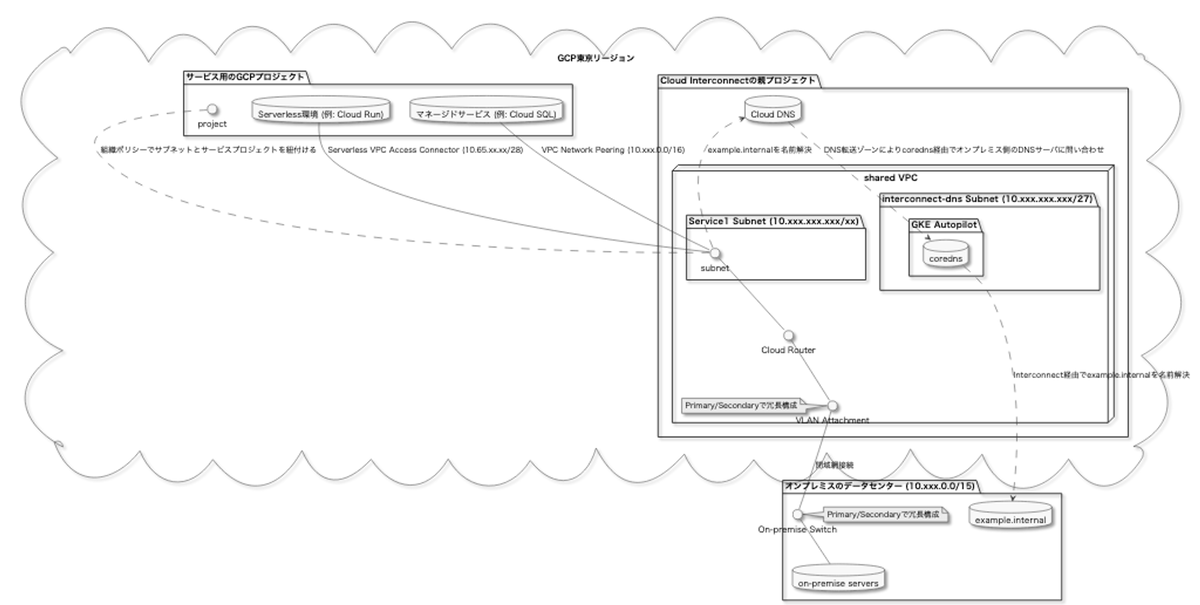
下記の構成が実際に作ったものになります。この後の説明はこの構成図を参照しながら読んでください。
オンプレミスのデータセンターとAWS
オンプレミスのデータセンターとGoogle Cloud
備考
ここに限ったことではないですが、記事内で単に「インターコネクト」と書いた場合はオンプレミスのデータセンターとパブリッククラウドとのインターネットを通らない閉域網接続のことを指します。(AWSのDirect ConnectやGoogle CloudのCloud Interconnectに関係ない総称みたいなもの)
Pastelaやpixivcobanで実現したかったことがパブリッククラウドからオンプレミス側にあるアカウント基盤や決済基盤のサービス(下記の図の example.internal の部分)を利用することだったため、オンプレミスからRoute53やCloud DNSの限定公開ゾーンに対してインターコネクトで通信するようなケースは要件になかったので考慮していません。
採用理由
インターコネクト or VPN
インターコネクトのような閉域網接続行うためにはVPNを利用するという選択肢もありました。
しかしVPNだとインターコネクトに比べてサービスで利用するための十分な帯域と品質を確保できないため、インターコネクトを開通することにしました。
Direct Connect, Direct Connect Gateway or Transit Gateway
AWSでインターコネクトを実現するためには下記の3つの手法があります
このうちDirect Connectは後述の複数アカウントの対応が難しかったので不採用になりました。
Direct Connect Gatewayだと1つのVGW(バーチャルプライベートゲートウェイ)に接続できるVPCの数に上限があります。そのため接続できるVPCの上限がないTransit Gatewayを利用したかったのですが、契約当時はキャリアが対応していなかった*2ためDirect Connect Gatewayを採用しました。
余談1
調査した時は1つのVGWに接続できるVPCは10個までだったのですが、現在は20個まで接続できるようになっているようです。
余談2
弊社のオンプレミス環境はIDCフロンティアのデータセンターを利用していますが、AWSやGoogle Cloudとの閉域網接続には「バーチャルブリッジ インターコネクト:メガクラウド」を利用しています。
AWSとGoogle Cloudでの実装差異
AWSとGoogle Cloudではクラウドの設計思想からして異なるので当然実装方法も異なります。ここでは前述の構成図をベースにどのような実装差異があるかを解説します。
インターコネクトの回線を管理する部分とサービス側が管理する部分を分ける
ピクシブでは開発環境と本番環境とでAWSアカウント(Google Cloudプロジェクト)をわけることが多いです。
そのため、Direct Connect GatewayやCloud Interconnectの回線自体を管理する親アカウント(親プロジェクト)を1つずつ用意して、それを他のAWSアカウントやGoogle Cloudプロジェクトから利用した方が数が増えた時に柔軟に対応できて合理的だと判断しました。
後の方でも書きますが、インターコネクトの設定はオンプレミス側にある数百台のサーバに対してAnsibleで設定変更を行う必要があるため、インターコネクトを利用したいサービスが増えた時に都度開通作業も行うのは現実的ではありません。
弊社の場合、インターコネクト開通時にデータセンター側で機器などの初期費用も発生するため頻繁に機器を増やしたくないという事情もありました。
VPC
AWSでもGoogle CloudでもVPCの中でアプリケーションを動かすのは一緒です。
しかし、インターコネクトを利用する場合VPCがどこのAWSアカウント(Google Cloudプロジェクト)で管理かが大きく異なります。
AWSの場合Direct Connect Gatewayを管理するAWSアカウントとVGWを管理するAWSアカウントが異なっていてもいいので、VPCはサービス側のAWSアカウントに置けます。
サービス側はインターコネクトを使わない場合と変わらないいつものやり方でインフラの構築ができます。
しかしGoogle Cloudの場合、1つのInterconnectに対して接続できるVLAN Attachment(AWSにおけるVGWのようなもの)の数に上限がありました。そのため、インターコネクトの利用サービス数が増える度にVLAN Attachmentの数を増やさないためにShared VPCを利用してインターコネクトを利用する全てのサービスで同一のVPCを利用することにしました。
この辺の構成はZOZOさんの下記のエントリがとても参考になりました。
実際にピクシブではこの記事の「Shared VPCを使った構成にする案」に近い構成を採用しています。
クラウドからオンプレミスのDNSを参照する
例えばクラウドで動いているアプリケーションから foo.example.internal(オンプレミス内のサービス)のAPIを利用する場合には下記のようなフローになります。
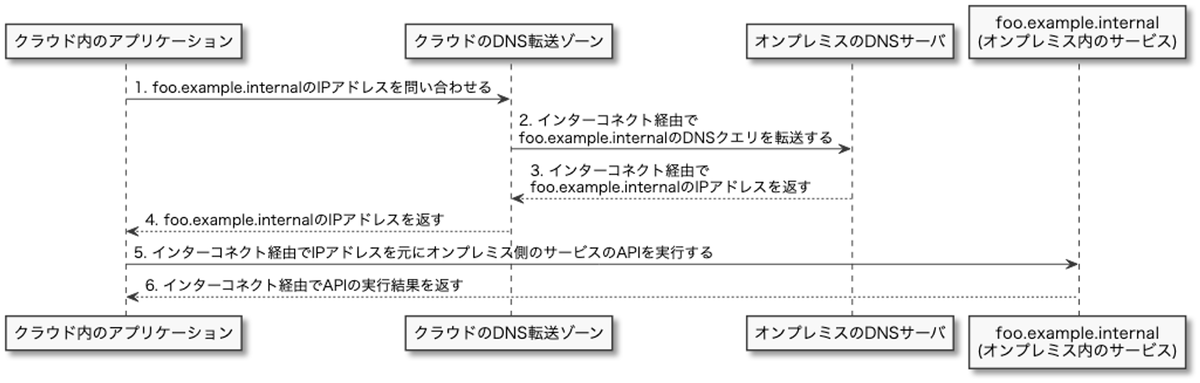
クラウドからオンプレミス側のDNSを参照する場合、AWSではRoute53 Outbound Resolverを、Google CloudではCloud DNSのForwarding zoneを利用してオンプレミスのDNSサーバにDNSクエリを転送することになります。
しかし、Route53 Outbound ResolverとCloud DNS Forwarding zoneとでは微妙に仕様が異なったためここで1つ苦労がありました。
AWSのRoute53 Outbound ResolverはVPCに関連付けられます。
そのため、前述の図の「2. foo.example.internalのDNSクエリを転送する」はオンプレミスから見るとVPCのCIDR内のIPアドレスからやってくることになります。
しかしGoogle CloudのCloud DNSはVPCに紐づけられていないため、35.199.192.0/19(Cloud DNSのCIDR)内のIPアドレスから返ってくることになります。
この仕様は下記の記事が詳しいです
35.199.192.0/19はCloud Routerで広告できるのでインターコネクトを通すことはできます。
しかし、35.199.192.0/19 がインターコネクトでの想定ネットワークレンジに含まれておらず、オンプレミスネットワークでは 35.199.192.0/19 の取り扱いをどう扱うかが難しいという問題がありました。
インターコネクトの機器が1つだけなら問題なかったのですが、今後インターコネクトを増設してオンプレミス側の機器が増えた場合に困ることが予想されました。
説明が難しいのですが、オンプレミス側では35.199.192.0/19からやってきた通信の戻り先は1つの機器に固定される(というか、static routesは同じCIDRからやってきた通信に対して複数の戻り先を設定できない)ため下記のようなことが発生してしまいます。
- Google Cloud → Cloud DNS → インターコネクトA(今回契約した機器と回線) → オンプレミスのDNSサーバ → インターコネクトA → Google Cloud
- Google Cloud → Cloud DNS → インターコネクトB(今後新しく契約する場合の機器と回線) → オンプレミスのDNSサーバ → インターコネクトA → Google Cloud
- インターコネクトAで障害が起きた時に、インターコネクトB側のルートも正常なのに引きづられて障害になってしまう。
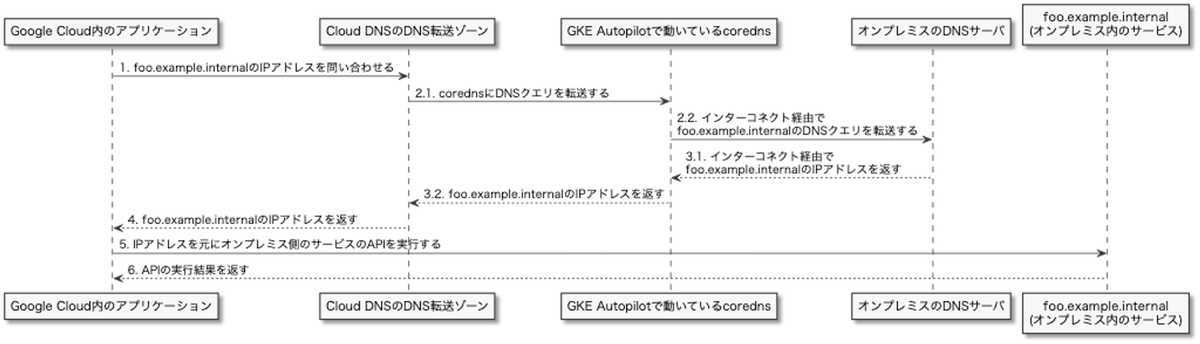
この問題を解決するにはVPCの中に自前でDNSサーバを立てて、Google Cloud内からオンプレミスのDNSを解決する時だけCloud DNSではなくそのDNSを使う必要がありました。
いくつかやり方は検討したのですが、管理のしやすさからGKE Autopilotのクラスタ内でcorednsを動かすようにしました。
coredns側は下記のようなCorefileを利用し、example.internal へのDNSクエリをオンプレミス側のDNSサーバにforwardしています。
.:53 {
errors
health {
lameduck 5s
}
ready
# NOTE: Datadogでcorednsの監視を行うためにprometheusのエンドポイントを有効化している
# c.f. https://docs.datadoghq.com/ja/integrations/coredns/
prometheus 0.0.0.0:9153
# NOTE: オンプレミス側のDNSサーバは冗長化されているためそれぞれのIPアドレスを指定
forward example.internal 192.168.xxx.yyy:53 192.168.xxx.zzz:53
cache 30
loop
reload
loadbalance
}
corednsではTCPとUDPの53番ポートでそれぞれリクエストを受け付ける必要があったので、静的内部IPアドレスを作成して内部アプリケーションロードバランサーに割り当てています。
下記のようにCloud DNSとオンプレミスのDNSサーバの間にcorednsを挟みました。
また、GKE Autopilotで動いているcorednsのpodからオンプレミスのDNSサーバに通信する時に送信元のIPアドレスがマスカレードがされないことにより、podのIPアドレスでオンプレミスに通信してしまうという事象が発生しました。(オンプレミスにはインターコネクトで広報しているGKE クラスタのNodeのIPアドレスで通信したい)
そこで https://cloud.google.com/kubernetes-engine/docs/how-to/egress-nat-policy-ip-masq-autopilot?hl=ja#edit-default-egress-nat-policy を参考にし、下記のようにオンプレミス側で利用しているCIDRをNoSNATから除外しました。
apiVersion: networking.gke.io/v1 kind: EgressNATPolicy metadata: name: default spec: action: NoSNAT destinations: # NOTE: デフォルトではGKEクラスタには下記のCIDRがNoSNATに登録されているが、 # 192.168.0.0/16はオンプレミス側で利用しているためNoSNATから削除することで # マスカレードされる(NodeのIPアドレスがオンプレミスに伝わる)ようにする - cidr: 10.0.0.0/8 - cidr: 172.16.0.0/12 # - cidr: 192.168.0.0/16 - cidr: 240.0.0.0/4 - cidr: 192.0.2.0/24 - cidr: 198.51.100.0/24 - cidr: 203.0.113.0/24 - cidr: 100.64.0.0/10 - cidr: 198.18.0.0/15 - cidr: 192.0.0.0/24 - cidr: 192.88.99.0/24
この2つの対応によりオンプレミスのDNSサーバはVPCのCIDRでDNSクエリを受け取ることができるようになりました。
オンプレミス側の作業内容
インターコネクトの開通にはAWSやGoogle Cloudだけでなくオンプレミス側の作業も行いました。
具体的にはオンプレミスにある数百台のサーバの/etc/network/if-up.d/static-routesに下記のようなstatic routeの設定を追加しました。
ip route add table main 10.xxx.0.0/13 dev eth0 via 192.168.xxx.xxx
本来的にはラックのネットワーク機器で解決できた方がよいのですが、歴史的経緯により各サーバが色々なネットワークへのルーティングの設定を持っているため /etc/network/if-up.d/ にスクリプトを配置してそこで設定を行なっています。説明のためにだいぶ簡略化して書いてますが、実際は送信元のゲートウェイ(viaの後ろのIPアドレス)ごとに5〜6個追加しています。
さすがにオンプレミスのサーバ全台ともなると台数が多すぎてAnsibleでも結構時間がかかったのですが、無事にサーバ全台に設定を適用できました。
最後に
元々この記事の内容は2024年9月20日に開催予定のPIXIV DEV MEETUP 2024で話すつもりの内容でした。
30〜40分枠の心づもりでプロポーザルを出したところ、なんとキーノートスピーカーとして抜擢されました。
キーノートスピーカーとして登壇させていただくことは非常に光栄なのですが、キーノートは1人あたりの持ち時間が5〜6分しかなくて明らかに喋る時間が足りないためこの場を借りて供養させていただきました。
PIXIV DEV MEETUP 2024は人生初のキーノートで、まさに貴重な基調講演というやつなので来られる方は大いに期待してください!
ピクシブでは複数クラウドのインターコネクトに興味がある人を募集しています。
*1:例えばBigQueryと密に連携させることが分かってる場合はGoogle Cloudに統一した方が何かと便利なのでピクシブではGoogle Cloudを利用することが多いです
*2:今は対応している



