はじめに
こんにちは。インフラ部のlyluckです。
この記事ではArgo RolloutsのRolloutがProgressDeadlineExceededによってDegradedになってしまう現象と、その対策について紹介します。
背景
ピクシブではKubernetesクラスタ内の一部のアプリでArgo RolloutsのRolloutを使ってblue-greenデプロイをしています。
Argo Rolloutsとはblue-greenデプロイや、canaryデプロイなどの便利なデプロイ機能をKubernetesに追加してくれるツールです。その中心となるリソースがRolloutです。Podの数を管理するという点でDeploymentと似ていますがデプロイの戦略が選べたり、細かなデプロイステップの制御ができたりします。
Argo Rolloutsをv1.7.1にバージョンアップしたところ、Rolloutのスケール時に
ProgressDeadlineExceeded: ReplicaSet "xxx" has timed out progressing.
というエラーが発生し、status.phaseがDegradedとなってしまうという現象が起きました。
ProgressDeadlineExceededとはRolloutの更新処理にかかる時間がprogressDeadlineSecondsを超えると発生するエラーです。Podの起動が遅いなどの理由で発生してしまう可能性はありますが、発生後でもPodが正常に起動完了すればエラーは解消するはずです。
しかし問題のRollout配下のPodは、RolloutがDegradedにも関わらず全てHealthyでした。RolloutをRestartしてみるとDegradedは解消します。この現象はおそらくこのIssueが挙げているArgo Rolloutsのバグです。
RolloutがDegradedになることでアラートが発火しがちでした。日に2、3回程度発火し、その度に手動でRolloutのRestartを行っていました。そのためArgo Rolloutsの問題が修正されるまでの応急処置として対策を考えました。
対策
RolloutがProgressDeadlineExceededによってDegradedになったことを検知して、自動でRestartを実行する仕組みを作りました。
Degradedの検知にはArgo CD Notifications(Argo CD v2.11.4)を、Restartの実行にはArgo Events(v1.9.2)を使いました。Kubernetesのバージョンは1.29.6です。
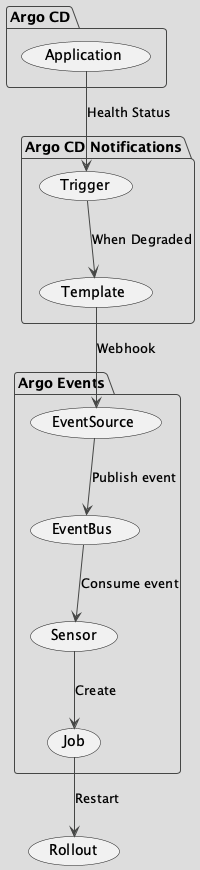
図解
詳細
KubernetesクラスターへのアプリケーションのデプロイにはArgo CDを利用しています。 Argo CDにはApplicationというリソースがあります。これはアプリケーションを構成するマニフェストのグループです。
Applicationに問題のRolloutが含まれていた場合、それがDegradedになるとApplicationのhealthもDegradedになります。このApplicationのhealthの変化をArgo CD Notificationsでキャッチします。
Argo Rollouts NotificationsでRollout自体の変化をキャッチすることもできたのですが
- Argo Rollouts Notificationsは未使用なので新しい管理対象を増やしたくない
- Rollout単位の設定を書きたくない
という理由で見送りました。
Argo CD Notificationsの設定は以下です。
apiVersion: v1 kind: ConfigMap metadata: name: argocd-notifications-cm namespace: argocd data: service.webhook.rollouts-timeout: | url: "http://rollouts-timeout-event-source-eventsource-svc.argo-events.svc:12000" trigger.custom-app-health-degraded: | - when: app.status.health.status == 'Degraded' send: - custom-app-health-degraded template.custom-app-health-degraded: | # 略 ... webhook: rollouts-timeout: method: POST path: / body: | { "project": "{{.app.spec.project}}", "namespace": "{{.app.spec.destination.namespace}}", "app": "{{.app.metadata.name}}", "health": "{{.app.status.health.status}}" }
trigger.custom-app-health-degradedはTriggerです。 notifications.argoproj.io/subscribe.custom-on-health-degraded.rollouts-timeout: "" というアノテーションが付与されているApplicationがDegradedになったとき、template.custom-app-health-degradedというTemplateを使ってメッセージを作ります。
template.custom-app-health-degradedにはWebhookを定義します。service.webhook.rollouts-timeoutのurlに向けて、記述の通りの内容のHTTPリクエストを送ります。
そのurlはArgo EventsのEventSourceです。
apiVersion: argoproj.io/v1alpha1 kind: EventSource metadata: name: rollouts-timeout-event-source namespace: argo-events spec: # Service rollouts-timeout-event-source-eventsource-svc が生まれる service: ports: - port: 12000 targetPort: 12000 webhook: rollouts-timeout: port: "12000" endpoint: / method: POST
これでHTTPリクエストがイベントに変換されます。そのイベントはSensorが消費します。
apiVersion: argoproj.io/v1alpha1 kind: Sensor metadata: name: rollouts-timeout-sensor namespace: argo-events spec: template: # Job 生成に必要 serviceAccountName: rollouts-timeout-sensor dependencies: - name: rollouts-timeout eventSourceName: rollouts-timeout-event-source eventName: rollouts-timeout transform: # template.custom-app-health-degraded のリクエストボディを取り出す jq: ".body" triggers: - template: name: restarter k8s: operation: create source: resource: apiVersion: batch/v1 kind: Job metadata: namespace: argo-events generateName: rollouts-timeout-sensor-restarter- spec: ttlSecondsAfterFinished: 600 activeDeadlineSeconds: 300 backoffLimit: 2 template: spec: # Rolloutの取得と再起動に必要 serviceAccountName: rollouts-timeout-sensor restartPolicy: Never containers: - name: main image: debian:bookworm-slim args: - "project" - "namespace" - "app" - "health" command: - /usr/local/bin/restart-rollouts volumeMounts: - name: rollouts-timeout-sensor-cm mountPath: /usr/local/bin/restart-rollouts readOnly: true subPath: restart-rollouts volumes: - name: rollouts-timeout-sensor-cm configMap: defaultMode: 0777 name: rollouts-timeout-sensor-cm parameters: - src: dependencyName: rollouts-timeout dataKey: project dest: spec.template.spec.containers.0.args.0 - src: dependencyName: rollouts-timeout dataKey: namespace dest: spec.template.spec.containers.0.args.1 - src: dependencyName: rollouts-timeout dataKey: app dest: spec.template.spec.containers.0.args.2 - src: dependencyName: rollouts-timeout dataKey: health dest: spec.template.spec.containers.0.args.3
Kubernetes Object Triggerを使ってJobを作ります。Jobのargsにはイベントから取り出した値を渡します。例えばmainコンテナのargsの1つ目には "project" と書いてありますが、実際にはイベントから取り出した値に置換されます。つまり
{ "project": "Example", "namespace": "Hello", "app": "World", "health": "Degraded" }
というイベントであればmainコンテナは
/usr/local/bin/restart-rollouts Example Hello World Degraded
というコマンドを実行します。
このrestart-rolloutsというスクリプトの内容は以下です。
apiVersion: v1 kind: ConfigMap metadata: name: rollouts-timeout-sensor-cm namespace: argo-events data: restart-rollouts: | #!/bin/bash set -ex set -o pipefail apt update apt install -y curl jq # kubectlをインストール # https://kubernetes.io/ja/docs/tasks/tools/install-kubectl-linux/ curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" chmod +x ./kubectl mv ./kubectl /usr/local/bin/kubectl # argo rolloutsのkubectl pluginをインストール # https://argo-rollouts.readthedocs.io/en/stable/installation/#manual curl -LO "https://github.com/argoproj/argo-rollouts/releases/latest/download/kubectl-argo-rollouts-linux-amd64" chmod +x ./kubectl-argo-rollouts-linux-amd64 mv ./kubectl-argo-rollouts-linux-amd64 /usr/local/bin/kubectl-argo-rollouts kubectl argo rollouts version # 与えられた名前空間にあるDegradedなRolloutを再起動する namespace="$2" names="$(mktemp)" kubectl get rollout -n "$namespace" -o json | jq '.items[] | select(.status.phase == "Degraded" and (.status.message | test("ProgressDeadlineExceeded"))).metadata.name' -r > "$names" # 再起動対象のRolloutがいなければ正常終了させる if [ -s "$names" ] ; then cat "$names" | xargs -n 1 kubectl argo rollouts -n "$namespace" restart fi
RolloutをCLIからRestartするにはkubectl pluginが必要なのでインストールします。
DegradedなApplicationの名前空間からDegradedなRolloutを探し、その理由がProgressDeadlineExceededであれば、これをRestartします。
SensorがこのJobをCreateするのと、このJobがRolloutをGetしてRestartするのに必要なServiceAccountは以下のとおりです。
apiVersion: v1 kind: ServiceAccount metadata: name: rollouts-timeout-sensor namespace: argo-events --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: rollouts-timeout-sensor namespace: argo-events rules: - apiGroups: - batch resources: - jobs verbs: - create --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: rollouts-timeout-sensor namespace: argo-events roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: rollouts-timeout-sensor subjects: - kind: ServiceAccount name: rollouts-timeout-sensor namespace: argo-events --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: rollouts-timeout-sensor rules: - apiGroups: - argoproj.io resources: - rollouts verbs: - get - list - update - patch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: rollouts-timeout-sensor roleRef: kind: ClusterRole name: rollouts-timeout-sensor apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: rollouts-timeout-sensor namespace: argo-events
終わりに
この記事ではDegradedなRollloutを検知して、自動でRestartする仕組みを紹介しました。