

はじめに
はじめまして。プラットフォーム開発部にてデータ基盤を整備しているkashiraとoystersukiと申します。
GoogleのデータウェアハウスサービスであるBigQueryを使用するとき、主に考慮しなければならないコストは二つあります。データの処理に関わる「コンピューティング」のコストと、データの保存に関わる「ストレージ」のコストです。
本記事では、このうちの「コンピューティング」のコスト・利便性に焦点を当て、ピクシブがどのような運用を行っているのか紹介します。
BigQueryのOn-demand, Capacityモデルの使い分けに困っている、どうやって利用者向けの環境を提供すれば良いのか分からないなどでお悩みの方に参考になれば幸いです。
BigQueryの料金体系について
BigQueryを利用する際には主にコンピューティングとストレージという2種類の料金が発生します。
ML機能を使ったり、リアルタイム関連の処理をする場合は他のコストも発生するのですが、その詳細は公式サイトをご確認ください。
コンピューティングの料金モデルは以下の2つがあり、利用者が選択する方法です。
- オンデマンド(On-demand pricing)
- データのスキャン量で料金が決定される
- 容量の料金(Capacity pricing)
- データを処理するスロットと呼ばれるリソースの使用量・購入量で料金が決定される cloud.google.com
スロットについて
コンピューティングの料金を話す上で、BigQueryのスロットという概念を理解する必要があります。
この記事で特に重要なのは以下の点です。 cloud.google.com
スロットはSQLクエリを実行するための計算リソース
Googleの一部のドキュメントではスロットのことを仮想CPUと表現されていることがありますが、実際はCPU以外の要素(RAM, Network)も含むので注意が必要です。 (参考)
On-demand, Capacityのどちらの料金モデルを選んでもデータの処理にスロットが使われる
On-demandモデルはスキャンしたテーブルのデータ量で料金が決定されますが、裏側の処理はスロットを使って行われます。On-demandの場合、料金に紐づかないリソースの上限があります。
スロットの上限の違い
Capacityモデルはスロットを購入するモデルなので、購入したスロット数が使える上限数になります。
一方で、On-demandモデルはGCPのプロジェクトあたり2,000、組織あたり20,000という上限があります。(参考)
それ以上、使いたい場合にはCapacityモデルへの移行が必要です。
またOn-demandモデルには2,000スロットの上限を超えて一時的にスロットたくさん確保するというバーストと呼ばれる挙動があるのも特徴です。 cloud.google.com
ピクシブでのOn-demandモデルとCapacityモデルの使い分け
ここからはピクシブで、どのようにOn-demandモデルとCapacityモデルを使い分けているのか?について説明します。
コンピューティング用プロジェクトとは?
まず、ピクシブではコンピューティング用プロジェクトと呼ばれるBigQueryのクエリを実行するためだけのプロジェクトを用意しています。
コンピューティング用のプロジェクトにはデータ(ストレージ)を置くことを禁止しています。
これはストレージとクエリを発行するプロジェクトが密結合していることで、クエリを発行するプロジェクトを差し替える際にストレージの移動まで発生することを避けるためです。
例えば、今までは全社のプロジェクトからクエリを発行していましたが、他部署のクエリの発行状況次第でスロットが確保出来ない事態が起きたとします。その際、期待する時間(SLA)通りに処理が終わらないので、別プロジェクトに切り替えて安定したワークロードを作って対処することが考えられます。
こういった場合、クエリの発行元とストレージを同じ場所にする移行作業を行うことで、以下のような問題が発生します。
- Storageがlong-term → activeになりストレージコストが一時的に上がる
- データのアクセス権限が引き継がれないので切り替え後に権限周りでエラーが出る可能性がある
- そもそもアクセス権限を網羅的に移行すること自体が大変
そのため、バッチで実行されるクエリを書くときには必ずプロジェクトIDを含めてアクセスするように書いてもらうことで移行作業が容易になるようにしています。
OKな例:
-- project-Aだけでなく、project-Bでクエリを実行しても正常に動く。 select * from `project-A.hoge.fuga`
NGな例:
-- project-Aでクエリを実行したときにのみ正常に動く。 -- project-Bなどでクエリを実行したい場合にはデータをコピーするか、 -- OKの例のようにproject-idを指定する必要がある select * from `hoge.fuga`
コンピューティング用プロジェクトの使い分けについて
ピクシブでは4種類のBigQueryのコンピューティング用プロジェクトを用意しています。
それぞれのプロジェクトは以下のように使い分けています。
何か特別なことがない限り、アドホックに分析する場合はOn-demandモデルの「ユーザー環境(制限環境)」、バッチを実行したい場合はCapacityモデルの「バッチ環境(Capacity環境)」という使い分けをしています。
ただし、「ユーザー環境(制限環境)」には事故防止のためスキャン量の制限をかけています。そのためスキャン量制限に引っかかる場合には別の「ユーザー環境(無制限環境)」を使う必要があります。
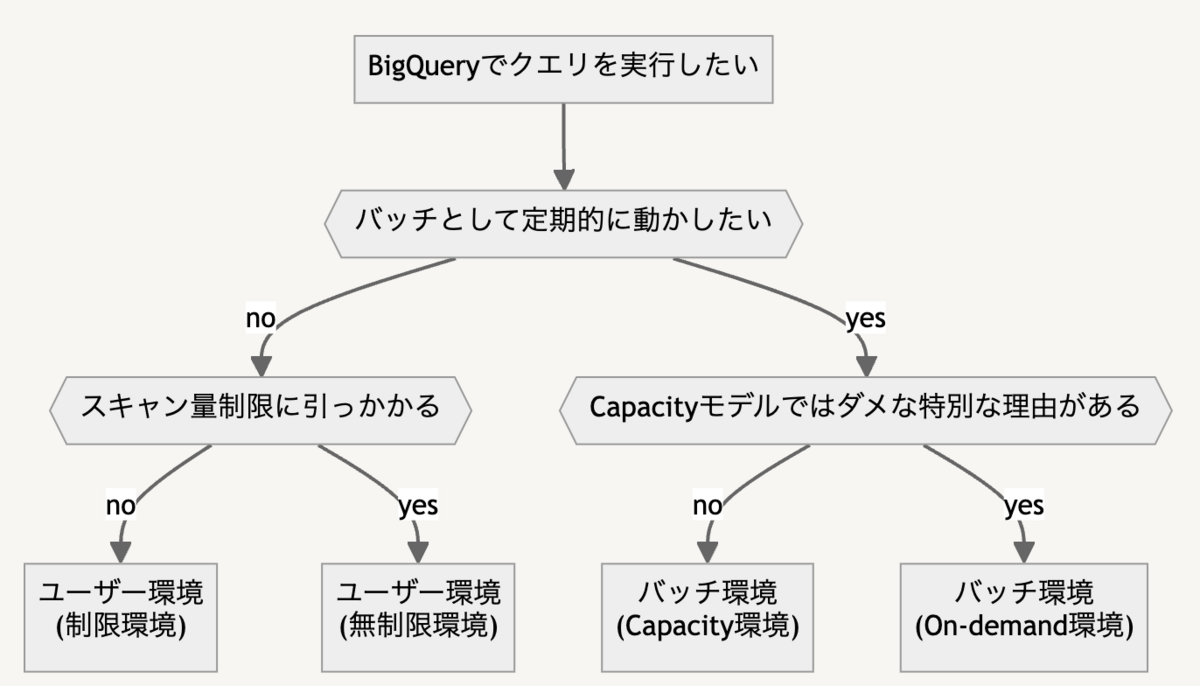
特徴は以下の表の通りです。
| プロジェクトの種類 | 課金モデル | スキャン量の上限 | メインの実行者 | どんなクエリが発行されるか |
|---|---|---|---|---|
| ユーザー環境 (制限環境) |
On-demand | あり | BigQueryを使う全社員 | スロットを意識していない利用者のアドホックなクエリ |
| ユーザー環境 (無制限環境) |
On-demand | なし | サービスアカウント BigQueryに詳しい利用者 | Lookerや開発時のクエリ ユーザー環境ではスキャン量の制限を超過するクエリ |
| バッチ環境 (Capacity環境) |
Capacity | なし | サービスアカウント | 最適化されたクエリ |
| バッチ環境 (On-demand環境) |
On-demand | なし | サービスアカウント | スキャン量に対してスロットの使用量が非常に多いクエリ (レコメンド系の複雑な計算処理など) |
バッチ環境について
バッチ環境は原則Capacityモデルを使うようにしています。
これは過去に、1つのOn-demand課金されるプロジェクトに全てのクエリを集約して、バースト機能ありきで運用していた際にバーストせずバッチの大規模遅延障害が起こったことに起因しています。
バーストは必ず保証されているものではないので、定期的に実行されるクエリはバッチ用のスロットを確保して安定的に動作するようにしたいという意図のもとCapacityモデルを使っています。
また、On-demandモデルで利用するスロットはGCP全体で共有されています。つまり、社内でスロットをたくさん使用していなくても社外でのスロットのリクエスト次第ではスロットの競合が発生します。
このようなスロットの競合が発生した場合、プロジェクトあたりのスロット上限(2,000スロット)が必ず保証されていない点もバッチにCapacityモデルを使っている理由です。
ただし、中にはレコメンド系の複雑な計算処理をSQLで行っているクエリもあり、そういったクエリはスキャン量に対してスロットを沢山使うためCapacityモデルで実行すると高額な請求につながります。
そういった特殊な用途のためにバッチ用のOn-demandプロジェクトも用意しています。
(インデックスやクエリチューニングをもっと頑張ればOn-demandと同じかそれ以上に安くなる可能性はありますが、現状はそこまで対応できていないという側面もあります)
ユーザー環境について
ユーザー環境はBI(Looker等)が実行するクエリか、社員がアドホックに分析するケースで利用されます。
ユーザー環境はOn-demandモデルを採用しています。理由や事故防止についてご紹介いたします。
Capacityモデルのメリット・デメリット
ユーザー環境にCapacityモデルを採用する際のメリットとして、以下のような点が挙げられます。
- コスト管理が容易になる
- 年間1,000スロット購入するとすれば、ドルで請求される費用は固定になるので予算を組み立てやすくなる
- 社員がコストを意識しなくても使える
- 上限が決まっているので、重いクエリやスキャン量の多いクエリを発行しても請求が増えない
- そのため、利用者が気軽に使える
- 社員やBIのクエリは優先度が低いので低めのスロットを割り当てて料金を抑えるという手法が取れる
- バッチ環境のスロットと共有できる
一方で、デメリットとして以下が挙げられます。
- 利用者がコストを意識しづらい
- On-demandと違って、UIから実行するクエリにいくら料金がかかるのかは不透明
- On-demandであればスキャン量から金額が逆算できるので、社内で利用する前に注意喚起が出来る
- SQLをチューニングするハードルが高い
- クエリのスロットを削減するにはBigQueryの仕組みやTipsを幅広く理解する必要がある
- 一方で、スキャン量はパーティションやクラスタリングを理解して適切に絞り込みをするだけで抑えられる上、dry-runでスキャン量も分かりやすく表示される

- 弊社ではBigQueryは申請のみで利用可能であり、利用者の理解度には差があるため、SQLチューニングの教育に多くの時間をかけることは現実的ではない
- スロットを沢山使うケースではコストが高い
ユーザー環境でOn-demandモデルを採用した理由
弊社では、Capacityモデルのデメリットのうち「SQLをチューニングするハードルが高い」を特に課題と捉えました。
ピクシブにおいてBigQueryの利用者の多くはビジネス・フロントエンドエンジニア・バックエンドエンジニアといったデータの非専門家です。(参考)
そのため、通常業務に加えて利用者にスロット時間を削るように教育するのは時間がかかる上に、「SQLチューニングのハードルが高いので、利用者がBigQueryで直接クエリを実行して分析するのは避ける」、「あまりよく理解せず共用のスロットを大きく消費して、他の利用者に迷惑かかるクエリを実行していた」といった問題に直面すると考えました。
今はOn-demandを採用しているので、下の画像のように利用者に分かりやすい形でクエリチューニングをお願いでき、問題がありそうなクエリは実行前に相談をいただけている状況です。
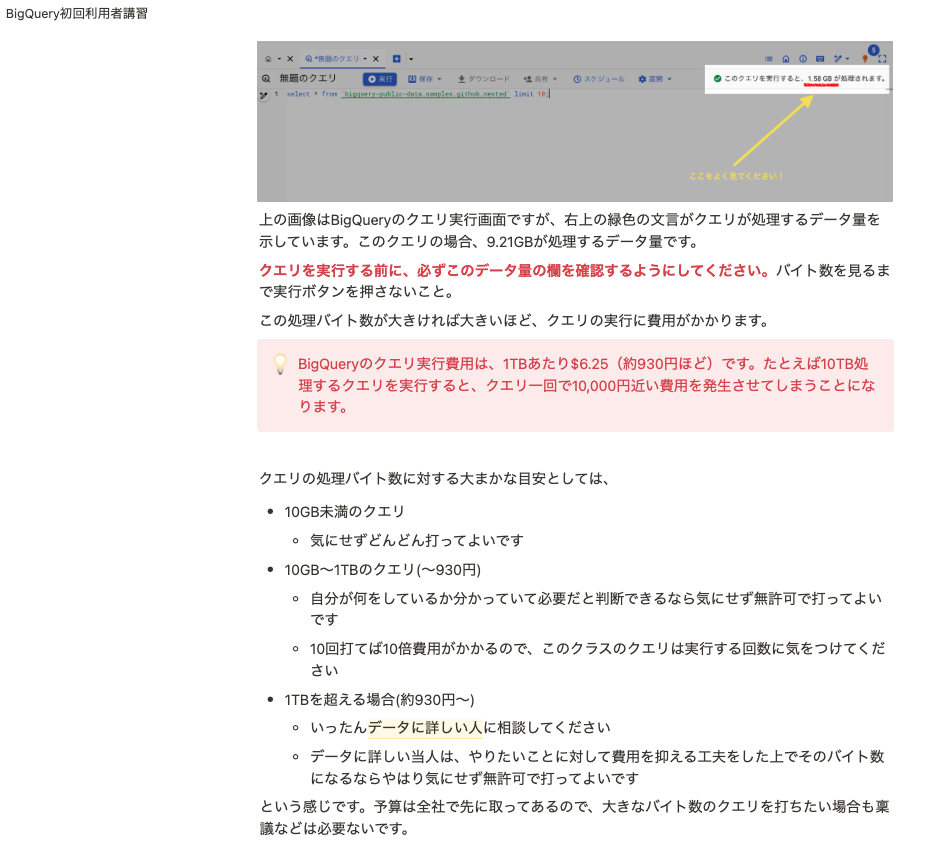
On-demandでは2,000スロット + バーストがあるので、よほどスロットを使うクエリを同時に動かされない限りは余裕がある状態で運用出来ています。
その一方で、Capacityモデルで2,000スロットを定額で購入すると、On-demandモデルで運用を行っていた時と比較してかなり高額になってしまいます。
またスロットのベースラインを0に設定しておき、必要な分だけスケールさせるオートスケーリングで運用することもできますが、これもOn-demandモデルよりはるかに高額になることがわかっているため、最大値が大きい場合には事故の元になります。
このような理由から弊社の運用においてはOn-demandモデルが適していると判断しました。現在はコストを抑えながら、利用者から「クエリの速度が遅い」などの不満が来ることなく運用できています。
将来的な需要によってCapacityモデルの環境を用意する可能性はありますが、少なくとも現時点では全てのユーザーには公開することはないでしょう。
ユーザー環境での事故防止対策について
前の項でもご紹介した通り、ユーザー環境のユースケースは基本的にユーザーのアドホックな分析もしくはBI利用時ですが、この際に気になるのはクエリのスキャン量です。
WebUIであるBigQuery Studioでは、スキャン前にバイト数が表示されるので事前に確認することはできますが、誤って非常に高額なクエリを実行してしまうこともあります。
またBI、特にLooker Studioは利用時にスキャン量を意識しづらく、意図せず日に10TiBものクエリを実行してしまった事例も過去にありました。
前の項ではユーザー環境にCapacityモデルを採用しなかった理由を解説しましたが、On-demandモデルはスキャン量に対する課金となるため、過大なスキャンを行わない対策も必要となります。
次の項ではどのように制限しているのかをご紹介します。
Query usage per day per userでスキャン量を制限する
On-demandモデルでスキャン量を制限するにはいくつかの方法がありますが「ユーザー/1日あたりのスキャン量を制限する」にはGCPの割り当てから「Query usage per day per userから制限を行う」以外の方法はありません。
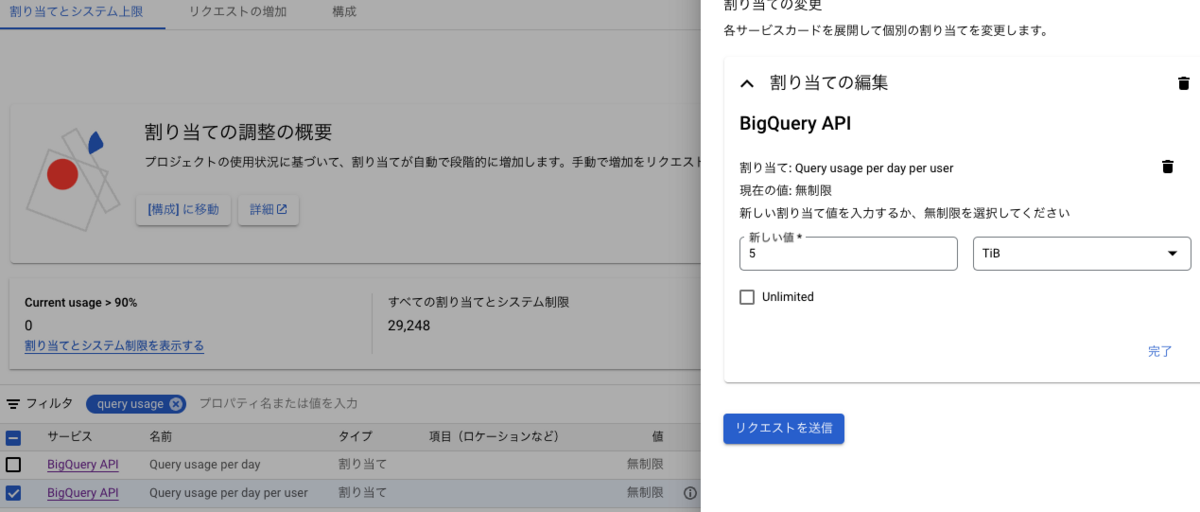
現在、弊社ではユーザーあたり1日で合計5TiBまでのクエリが実行可能です。この値はユーザー/1日あたりのスキャン量の合計値の99%パーセンタイルの値から算出しています。
結果的に、この手法を採用して良かったと思っています。明確に1日のクエリ上限が制定されるので、過大なクエリを実行してしまう心配はありません。加えて、dry-runによってスキャン量が事前に表示されるので「あと大体このくらいは使える」と意識することもできます。
ただ、設定には一点だけ注意が必要です。
当然といえば当然ですが、ユーザーだけではなくサービスアカウントも影響を受けてしまいます。
Query usage per day per userは特定のアカウントを除外することはできないので、job_project_idを他のプロジェクトに変更する等の対応が必要です。
仮に制限を設けたプロジェクトからクエリを実行しているサービスアカウントがあり、スキャン量がしきい値を超えた場合はバッチが止まってしまいます。
分析用データであればダメージも少ないですが、BigQueryで集計を行ってプロダクトのDBにReverse ETLを行っているようなバッチがあった場合はビジネス影響が大きいので気をつけましょう。
制限を超えたクエリを発行したい場合
スキャン量の制限を導入した一方で、「制限を超えたクエリを発行したい場合はどうするのか」と気になる方もいるのではないでしょうか。
実際にこのようなケースは存在しています。例えば、過去数年間にわたって分析を行いたい場合や、データマートをフルリプレイスする場合など、10TiBを超えるスキャン量になってしまう場合もあります。
この場合の対応として「事実上無制限にクエリが実行できる環境」を用意しています。前の項でご紹介した「無制限環境」がこれにあたります。
厳密にはこの環境にもユーザー/1日あたり75TiBの制限をかけていますが、事実上の無制限と言えるでしょう。
無制限環境を利用するには申請が必要となり、フローとしては以下のようになります。
- Slackでデータ基盤チームへ申請をしてもらう
- 特にフォーマットはなく、用途といつまで権限が必要なのかを聞いています
- terraformを用いて無制限環境のプロジェクトからBigQuery ジョブユーザー権限を期限付きで付与する
- よく使うのでterraformのmoduleにしています
- 申請者に利用方法・注意点をまとめたドキュメントを送り、利用をはじめてもらう
申請は必要ですが堅苦しいものではありません。スキャン量が大きなクエリの実行を不必要に制限するためではなく、リソースの適切な利用を促すためのものです。
現状でそこまで工数がかかっているわけではありませんが、今後はPAMをテストを兼ねて使ってみて、申請者・承認者の工数を減らせるとよいな、と考えています。
終わりに
今回の記事ではBigQueryのコンピューティングプロジェクトの運用方法について紹介しました。
ピクシブでは、一緒にプロダクトを盛り上げてくれる方を大募集しています。 ご興味のある方は、以下のリンクから是非ご応募下さい。 hrmos.co hrmos.co



