

こんにちは。
機械学習チームにてレコメンドの改善を行っているgumigumi4fです。
この記事では、Fluentdにて収集したログをBigQueryに挿入する際に使用しているプラグインを置き換えることによって、高スループットかつ低コストを実現した話について紹介します。
背景
pixivではアクセスログやアプリケーションログ等をBigQueryに収集し、分析できるような仕組みを構築しています。
BigQueryへアクセスログを挿入する際はFluentdとそのプラグインであるfluent-plugin-bigqueryを用いて直接BigQueryへ書き込むようになっていたのですが、その際にログ欠損が起こることが問題となっていました。
ログの欠損はピークタイムで発生しており、そのピークタイムのログの流量は概ね毎秒30000logとかなり多く、実際Fluentdのworkerプロセスが1workerあたりCPUを1コア恒常的に使い切っているなど頭打ちのような挙動をしていました。
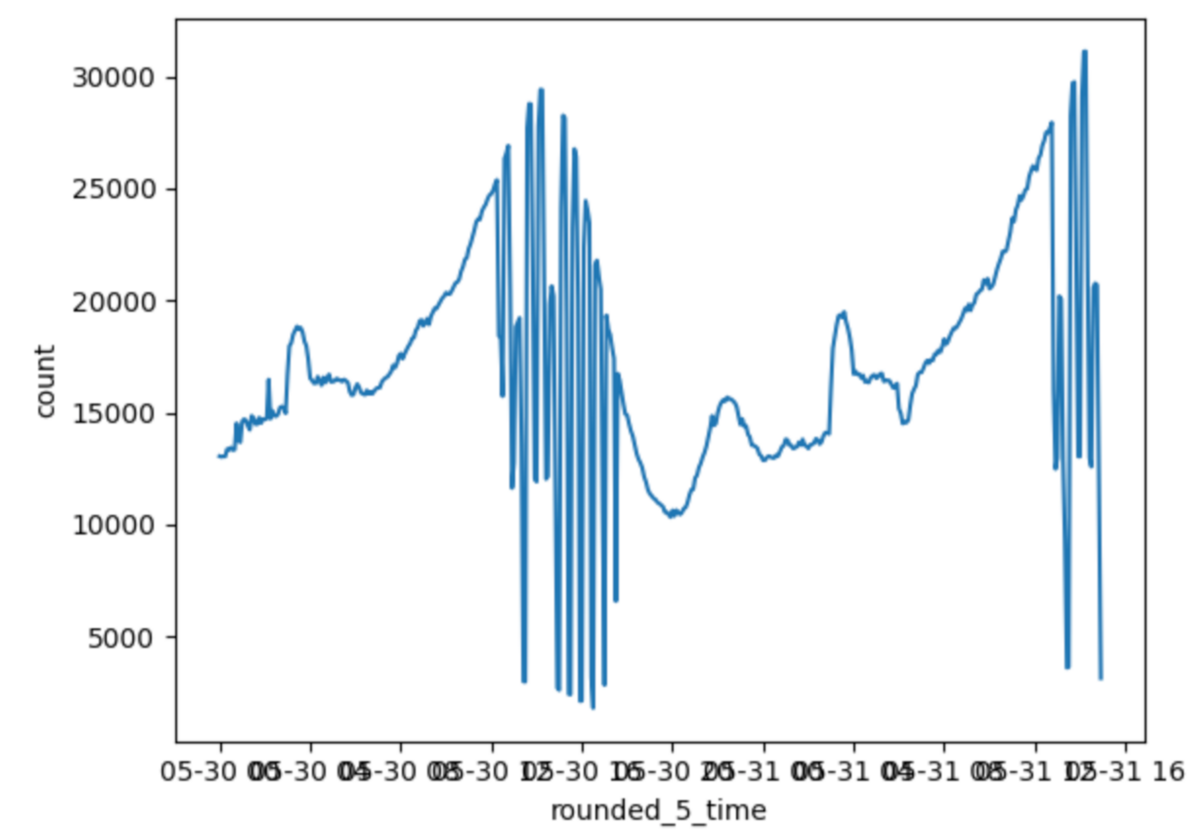
マシンスペックをより強化し、Fluentdのworkerを増やすことで解決ができる問題ではありましたが、すでに高性能なマシンを2台使用しており、今後のスケールを考えると大きな出費となることから、より高効率なソリューションも模索することとなりました。
代替案
より効率的にログをアップロードするための方法としてまず考えられたのが、バッチでのデータの挿入を行う方法でした。
fluent-plugin-bigqueryにはStreaming Insertを用いてリアルタイムでBigQueryにログを挿入する方法と、通常のバッチによってデータをロードする方法の2種類が実装されています。
大量のデータを挿入する際にはバッチを用いた方が良いとfluent-plugin-bigqueryのREADMEにも記載されており、また、Streaming Insertでの挿入は1GBのデータの挿入毎に$0.05かかるのに対して、バッチでのロードは無料とコストの面ではかなりメリットがあります。
しかしながらデメリットも存在し、特に1日1テーブル当たり1,500回までしかLoadできないという制限が存在します。
この制限により、Fluentdを複数ワーカーで動作させた場合数分毎にしかデータをロードできないため、不正検知等リアルタイムでの処理にデータを使えなくなってしまう欠点があります。
そのため、バッチを使用したロードは諦めざるを得ませんでした。
その他にも、ログ基盤を作り変えてしまう方法等様々模索しましたが、最終的にBigQueryにデータをリアルタイム挿入するための新しいAPIである BigQuery Storage Write API を用いる新たなFluentd向けプラグインを開発することにしました。
Storage Write API
Storage Write APIはStreaming Insertの後継となるAPIで高いスループットと低いコストを謳っています。
https://cloud.google.com/bigquery/docs/write-api?hl=ja
Streaming Insertではデータの送信にJSONを用いていましたがStorage Write APIでは通信にgRPCを用いるため、プラグインを置き換えることによって通信量が減りスループットの向上が期待できます。
また、Storage Write APIでは1GBのデータの挿入毎にかかるコストが$0.025とStreaming Insertに比べて半額のため純粋なコストの面でも優れています。
ちなみに、Storage Write APIを通してデータを挿入した場合、毎月2TiBまで無料なのでデータの量が少なければ無料で使うことが可能です。
一方でデメリットとして、Storage Write APIではgRPCを使用しており、データのシリアライズにProtocolBufferを使用する必要があります。
そのため、挿入するデータのスキーマをあらかじめ .proto ファイルに記述しコンパイルしておく必要があるなど、少し手間がかかるのが難点です。
開発したプラグイン
というわけで、Storage Write APIを介してBigQueryにデータを挿入する新しいFluentdのプラグインfluent-plugin-bigquery-storage-writeを開発しました。 github.com
開発したプラグインのスループットを確かめるため、GCP上に同じ条件でFluentdをセットアップしたインスタンスを用意し、BigQueryに対するデータ挿入のベンチマークを行いました。
ベンチマークにはpixivで実際にBigQueryに挿入していたデータを用いました。
アクセス日時やアクセス元のIPアドレス、リファラやUserAgentなどが含まれたレコードで、jsonに直すと1レコードあたり600byte前後になります。
Fluentdのsampleプラグインを用いてダミーのログを毎秒2000レコード生成し、そのログが各プラグインでBigQueryに何行挿入できたかを計測しました。
| 挿入できた行数 | 速度 (per 秒) | |
|---|---|---|
| 従来のプラグイン | 240,945 | 1003.9 |
| 新しいプラグイン | 424,027 | 1766.8 |
結果として新しいプラグインでは従来のプラグインに対して約1.7倍の量のログを同じスペックのマシンで挿入できることが確認できました。
実際には挿入するログのスキーマなどでスループットは上下するとは思いますが、少なくとも既存のプラグインと同等以上のスループットが期待できます。
使い方
先に記述した通りプラグインを使用するためにはBigQueryのスキーマに合わせて .proto ファイルを記述する必要があります。
下記に記載したものがBigQueryのスキーマとそれに対応する .proto ファイルの記述になります。
https://github.com/gumigumi4f/fluent-plugin-bigquery-storage-write/blob/master/proto/test_data.proto
各データ型の形式の変換はここのドキュメントで詳しく説明されています。
作成した .proto ファイルは protoc でruby用のコードにコンパイルします。
bundle exec grpc_tools_ruby_protoc -I proto --ruby_out=proto proto/test_data.proto
また、実際に投入するデータの形式も一部変更する必要があります。
例えば、BigQueryにStorage Write APIを経由してTIMESTAMPのデータを入力する場合、その形式をUnix Epoch Time (microseconds)でint64に格納し投入する必要があります。
これをFluentdで実現する場合は以下のようにrecord_transformerを書くと良いです。
<filter test>
@type record_transformer
enable_ruby
<record>
time ${(time.to_f * 1_000_000).to_i rescue nil}
</record>
</filter>
最後にoutputプラグインの設定を書いて完成です。
基本的にはStreamingInsertを使うBigQueryプラグインと同じ設定で問題ありませんが、先に生成したrubyのコードのパスを指定する必要があります。
<match test> @type bigquery_storage_write_insert auth_method application_default project hogehoge dataset fugafuga table foobar proto_schema_rb_path /hoge/huga/foobar.rb proto_message_class_name FooBar </match>
結果
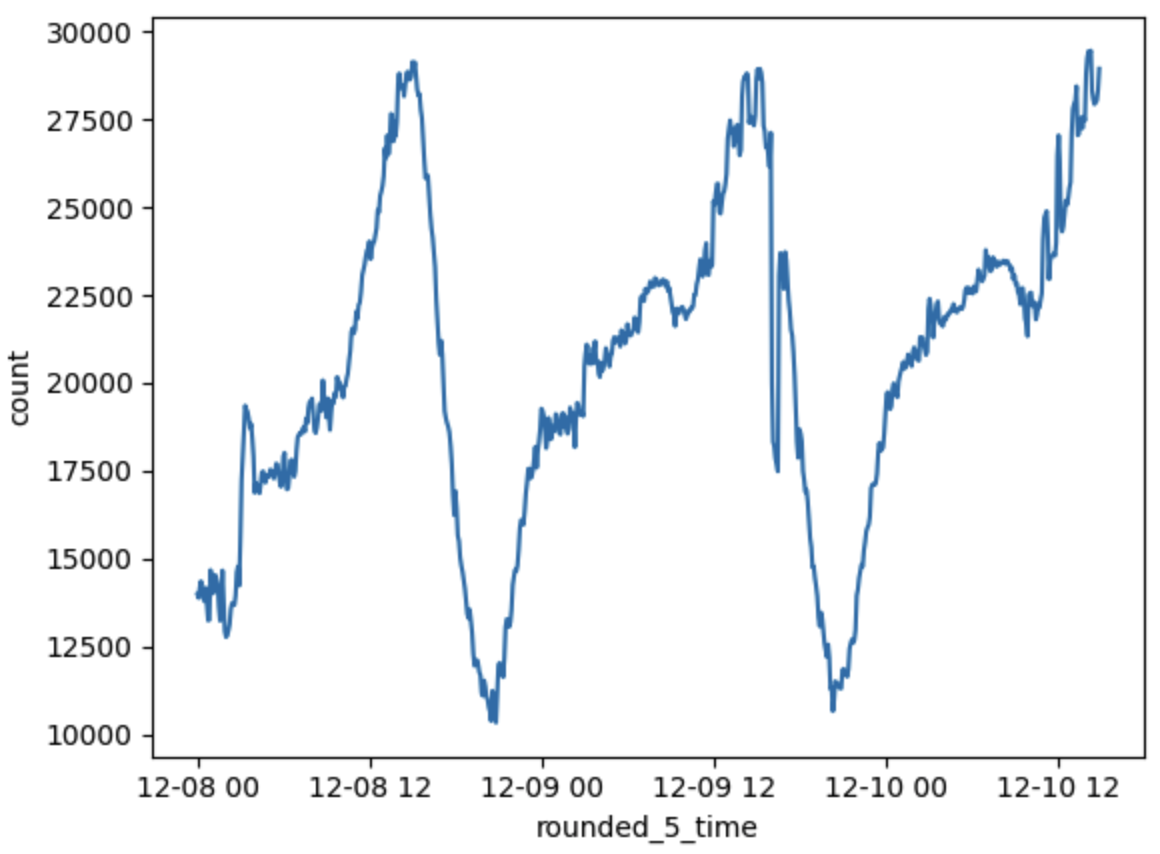
上記の結果に基づいて、実際に社内でつかっていたStreaming InsertプラグインをStorage Write APIプラグインに置換しました。
その結果、挿入されたログの流量がガタつくことがなくなり、欠損なく挿入することができるようになったことが確認できました。
また、Fluentdを稼働させているマシンのネットワークのアウトが半分程度になっており、オンプレのマシンとGoogle間の通信を半分以下に減らせていることが確認できました。
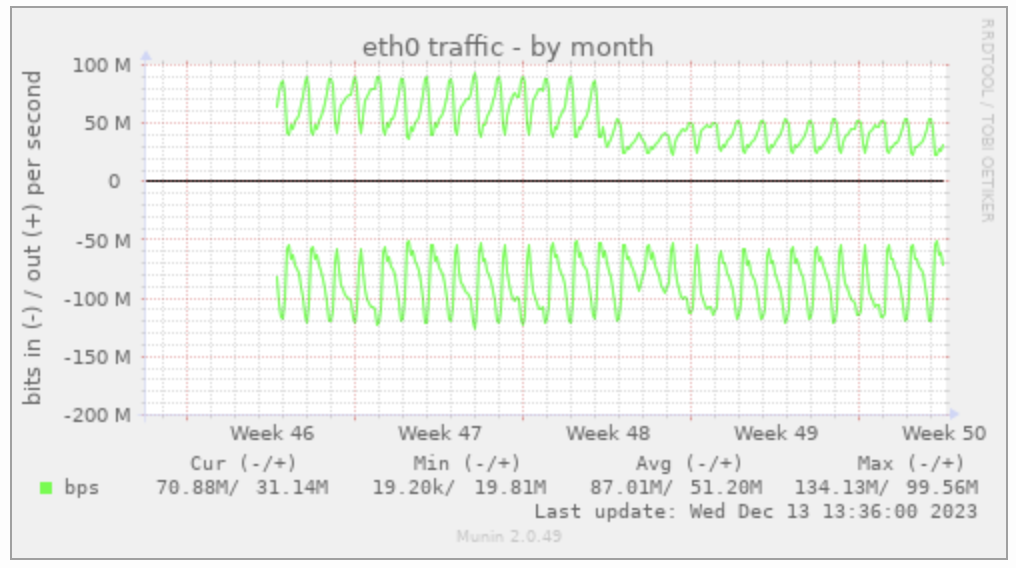
CPU使用率も若干微減しており、全体的なスループットの向上が確認できました。
更に、Streaming Insertをつかっていた料金約300,000円/月がなくなり、Storage Write APIの使用料が約100,000円/月と概ね200,000円/月のコスト削減ができました。
コストが半分以下になった理由は、Storage Write APIが毎月2TiBまで無料なこと、JSONに比べてProtocolBufferのほうがシリアライズ後の容量が小さくなったからなどが考えられます (実際のところは不明)。
最後に
Storage Write APIはそのドキュメントが少なかったりgRPCを使う関係で導入のハードルが高かったりするのですが、今回のプラグイン開発を通してStreaming Insertを置き換えるメリットがかなり多いことがわかったので、このプラグインを使用してよりStorage Write APIを有効活用してもらえればと思います。



