

はじめに
初めまして。プラットフォーム開発部にてデータ基盤の整備をしているazukiと申します。
今回はdbt(Data build tool)を導入した経緯と非中央集権的なdbtの使い方についてご紹介したいと思います。
今回は導入に関してまとめていますので、dbtの運用面の詳細は別記事で解説予定です。
データモデリングツール導入の背景
ピクシブではプロダクトの多さを理由に非中央集権データ組織を採用しています。
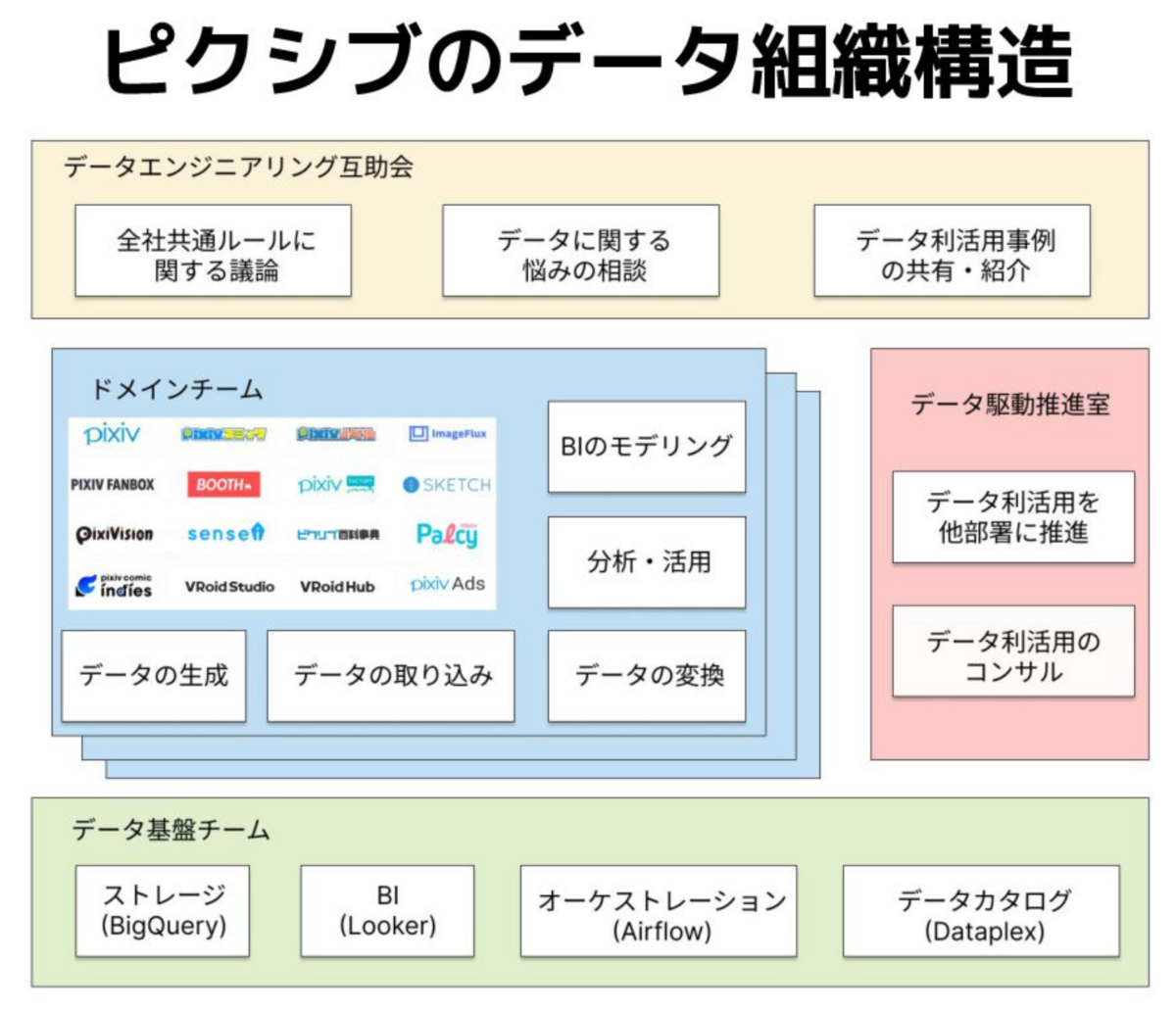
ドメインチームがメインでデータの取り組みやデータモデリングを行い、データ駆動推進室やデータ基盤チームはそのサポートや整備を担当しています。
その背景に関しては、【PIXIV MEETUP 2023】の方でお話していますのでぜひご覧下さい。 speakerdeck.com
今までBigQueryのデータ加工SQLは自社で開発したツールで管理していました。
pythonから変数埋め込みができるSQLを作成し、CI/CDで変更コミットがマージされた時にViewの更新、Airflowで定期的にテーブルの更新を行なっていました。
既存のツールでは、データリネージやドキュメント、テストのような機能がないことで整備されていないテーブルやビューが乱立することになり、誤った分析を行う可能性もありました。 またデータ駆動推進室・データ基盤チームといった社内のデータ整備を行うチームの運用コストが高くなり、データモデリングツールの導入が必要になりました。
ピクシブでの要件とツール選定
非中央集権データ組織として誰がどのようにツールを使うのかという部分を明らかにする必要がありました。
そこでツール導入する目的をWhy・Who・When・Whatの要件でまとめました。

それぞれの項目において実現可能なツールとしてdbt coreを採用しました。
比較対象としてdataformを検討していましたが、項目8や項目10との相性が悪く、弊社ではdbt coreを採用する方がメリットが大きいと感じました。

データモデリング整備
レイヤリング
dbtのベストプラクティスに従って、集計定義のレイヤーを分けました。
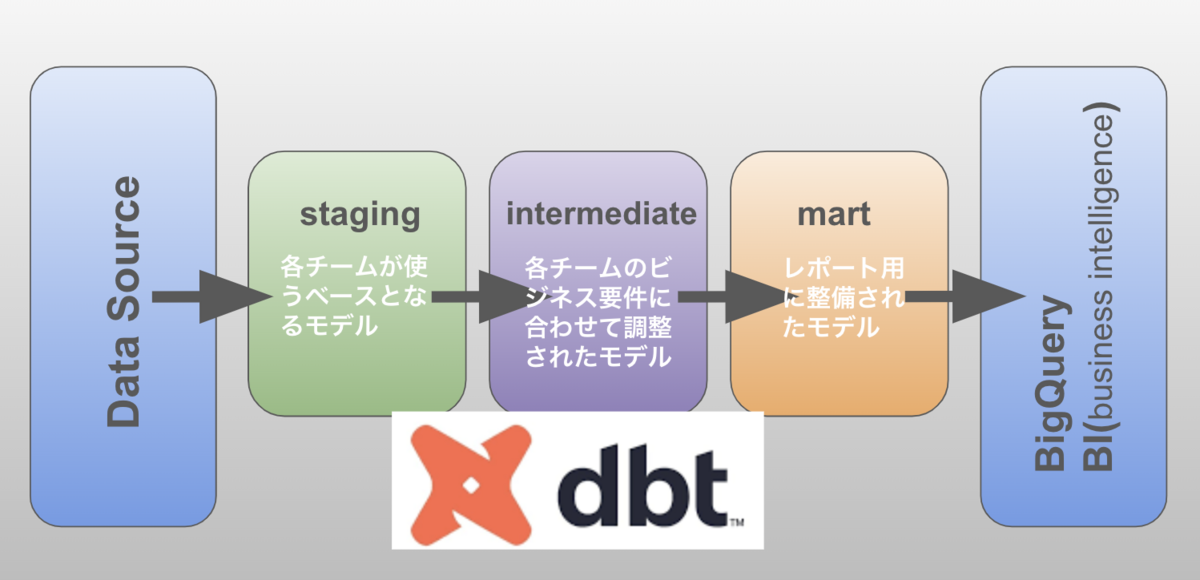
- staging
- カラム名の変更・カラムtypeの変換を行い、unique,やnot nullのtestを実行します
- 非中央集権データ組織とも相性が良く、stagingモデルを各チームで共有することでSSOT(信頼できる唯一の情報源)を実現します
- intermediate
- 各チームのビジネス要件に合わせた集計、抽出
- 不要なレコードを取り除いたり、ファンアウトの誤計算に対応する為の集計などを各チームが管理します
- mart
- BIなどレポート側が参照するデータ
- Star schemaを意識したモデリングを行っています。ディメンションテーブル、ファクトテーブルを作成し、エンドユーザーが集計しやすいデータマートを提供しています
非中央集権組織の使い方として、以下のルールを設けました。
- stagingは他部署も利用可能なモデル
- intermediate以降に関してはハブになるような特定のモデルを除いて、他部署は利用しない
データリネージ機能も活用することで開発時に容易に全体の把握ができるようになりました。
課題となっていたデータ基盤の運用コストもかなり軽減できる状態になりました。
tagでモデル管理
tags: - department - report - exclude_ci_test
- 部署のtag
- 部署内での管理単位
- 部署のtagで既に分かれているので、部内で自由に設定できます
- 主にairflowのDAGに合わせてtagを振っていきます
- hourly、every_day、monthlyなど実行タイミングもairflowと組み合わせることで管理できます
- システムに関するタグ
この3点をタグで管理することでモデル(SQL)の管理を行っています。
なぜこの3点で管理しているのかの理由に関しては別記事で紹介予定です。
依存関係(ref)
dbtの特徴としてテーブルを参照する際にdbtのモデルを指定します。
モデルを参照することによって、影響するモデルの管理やsourceの管理も容易になります。
with
import_stating_model_a as (
select * from {{ ref("stg_model_a") }}
),
import_stating_model_b as (
select * from {{ ref("stg_model_b") }}
),
import_stating_model_c as (
select * from {{ ref("stg_model_c") }}
),
非中央集権データ組織において、影響範囲を把握できるようにするという点が非常に重要です。データリネージ機能を活用し、データ活用の促進と運用コストの削減を実現しました。
クエリの部品化
dbtのmacro機能を使うことでクエリの部品化を行います。
特にGA4(Google Analytics 4)のデータなどは共通な部分も多く、スケールしやすい環境を整えることができました。
{% macro ga4_base_select_source() %}
parse_date("%Y%m%d", replace(_table_suffix, "intraday_", "")) as event_date,
timestamp_micros(event_timestamp) as event_timestamp,
event_name,
(...中略)
is_active_user
{% endmacro %}
dbt test
モデル定義のファイル内でuniqueやnot nullのテストも書けるのでテストの開発が容易にできます。
容易に開発できるというのも非常に魅力的です。
models:
- name: users
columns:
- name: user_id
tests:
- unique
- not_null
エコシステムの構築
ドメインチームが快適にdbtを利用する為に、データ基盤チームがエコシステムの導入・整備を行っています。
ソースコードの品質の担保と快適な開発環境を提供することで従来のシステムとの差別化も行っています。
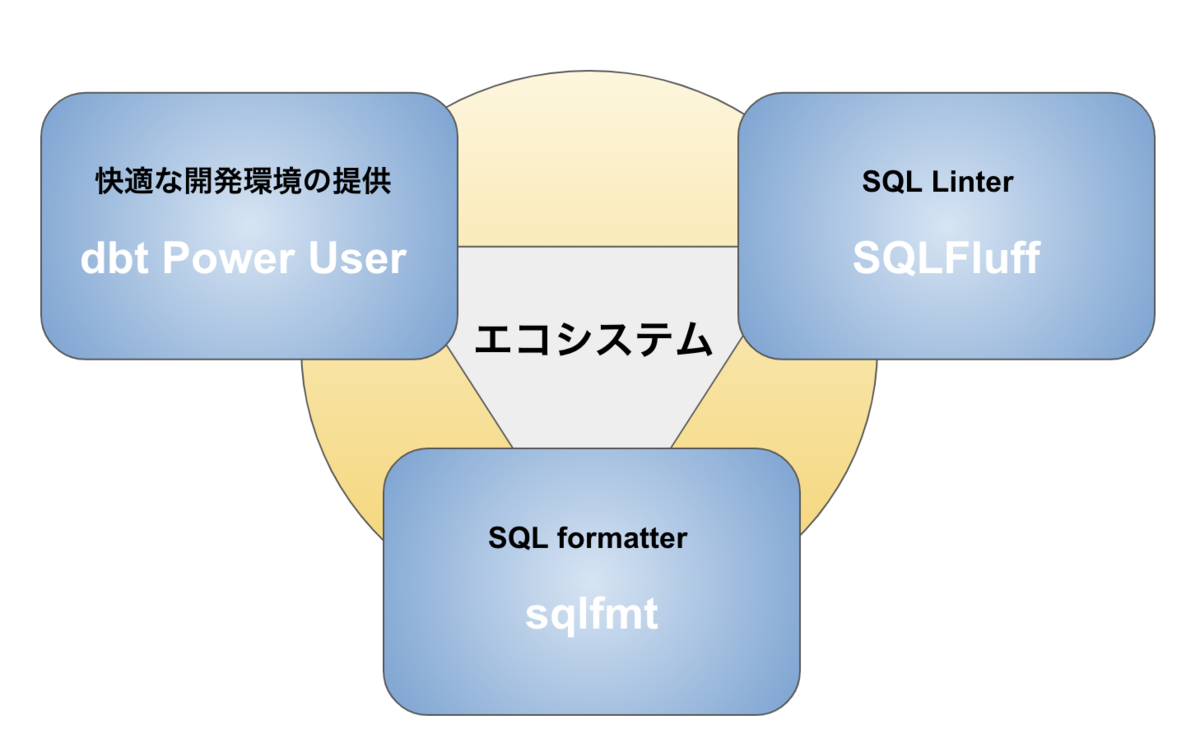
非中央集権データ組織でdbtを浸透させる為に行ったこと
ドキュメント整備
dbtのドキュメントをベースにデータ基盤チームが意識して欲しい箇所を社内wikiにまとめています。
ツールの導入や利用方法は勿論のこと、Star Schemaなど専門的な話も交えることで自然とデータモデリングを学べる環境を整えています。
勉強会
週に1回 読書会を開催しています。
現在読んでいる技術書はStar Schemaです。業務だけでは得られないデータモデリングの知識を身に付ける機会になっています。
疑問点や気づきを共有することで社内のデータコミュニティの活性化にも繋がっています。

まとめ
今回のinside記事ではピクシブにおけるdbt導入と非中央集権データ組織な使い方について紹介しました。 dbt導入に伴う依存関係の整理やtestの実施、非中央集権データ組織として意識した点について記載させて頂きました。 dbt導入でデータモデリングが楽になりました。しかし、dbtを導入しても解決できないことも多くあります。データ基盤は勿論のこと、特にデータ活用についてはこれからやっていくことが多く残っています。
データマートの拡充や自動化、データ基盤/データ活用 両方におけるデータマネジメントを進めて参ります。
ピクシブでは、一緒にプロダクトを盛り上げてくれる方を大募集しています。 ご興味のある方は、以下のリンクから是非ご応募下さい。



