

初めまして。プラットフォーム開発部で全社横断データインフラやデータマネジメントを担当していますkashiraです。
この記事では、先日のPIXIV DEV MEETUP 2024のLTで発表した「AirflowのKubernetes移行 ~ Kubernetesで運用するのは思ったより難しくない ~」について登壇内容を元に大幅に加筆修正を行い、文章にしたものです。
先日の発表では、時間の都合上話せなかったことが多くありました。そのため、この記事で移行についての補足を多めに入れています。
この記事がAirflowの運用に困っている管理者の方にとって少しでもお役に立てれば幸いです。
スライドは下記で公開しています。 speakerdeck.com
はじめに
ピクシブではデータパイプラインの基盤として、全社共通のAirflowをデータ基盤チームで運用しています。 個人的に特徴的だなと思っている点が、ピクシブでは全エンジニアがAirflow(+Embulk) を使って短時間でBigQueryに関連するデータパイプラインを作れるようにテンプレートを整備している所です。 実際にこのAirflowの利用者でデータを専門とする人はほぼいなくて、メインはバックエンド・フロントエンドエンジニア等のプロダクトに近いエンジニアです。
詳細は過去の発表をご覧ください。
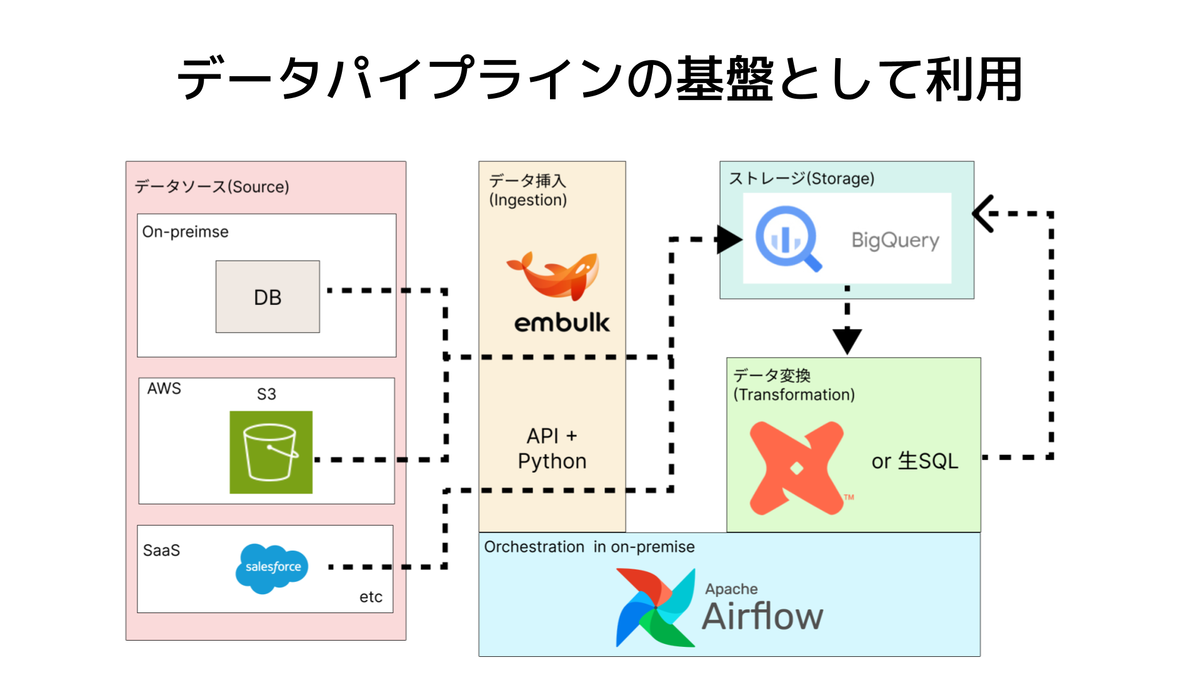
移行前の構成
ピクシブではオンプレミスの1つのサーバーに、Airflowの処理を全て集約して運用していました。(アクティブ・スタンバイ構成なので厳密に1つというわけではありません) これは、Airflowが導入された当初は利用者数・プロダクト数が限定されていた、負荷分散の仕組みがAirflowに足りていなかったなどの事情があります。 Airflowを取り巻く環境も大きく変わり、現状の構成では様々な問題が出始めたので、AirflowのKubernetes(以下k8s)化に踏み切りました。
移行前に抱えていた課題
課題は具体的には、以下のようなものです。
- リソース不足が原因だと思われる謎のスケジューラー停止が定期的に起こる
- 再起動すれば治ったが、問題が発生するのはバッチが集中する深夜なので、深夜にエラーに関するSlack通知を意識する必要がある
- 放置するとデータ遅延が大量発生する、リトライを手動で大量にかけるなどの対応が必要になり工数が取られる
- CPU不足によるタスクの遅延
- 社員数・プロダクト数が増えたことでワークロードが増え、期待した時間内にデータ連携が終わらないので、どうにかしたいという相談が増えた
- マイクロバッチ・SLA高めのワークロードなどのワークロードの特性が多様になった
- インフラがサーバーを管理し、データ基盤チームがAirflowというアプリケーションを運用しているのでサーバー関連のトラブルシューティングがしづらい
- インフラとデータ基盤チームは完全に別部署のチームなので、コミュニケーションにもハードルがあった
- スケールアウトできない

解決に向けて
検討
こういった課題を解決するために、まずはインフラのエキスパートであるインフラチームと相談し二つの案が出てきました。Google CloudのCloud Composerを採用する案と、オンプレのk8sの上にHelm管理で乗せる案です。
この二つを検討した結果、オンプレのk8sの上にHelm管理で乗せる運用が良さそうだという意思決定を下しました。
採用理由としては、以下になります。
- Cloud Composerではマネージドサービスに関連するネットワーク問題が解決できなかった
- メインのデータソースとなるMySQLの大半がオンプレDBで管理されている
- Cloud Composer等のマネージドサービスと接続するにはセキュリティ要件として専用線を使いたい
- ただし、Airflowのワークロードの特性上、特定の時間に大量のデータをバルクアップロードするので、つまらないようにネットワーク帯域を広く確保する必要がある
- 帯域を広く確保すると、忙しくない時間帯分の料金が有効活用できずに無駄なコストが多く発生する
- オンプレk8sがすでに実績を持って運用されている
- 社内に専門家がいるのでサポートを期待できる
- すでにArgoCD、クラスタとのDatadog連携などエコシステムが準備されている
- Helmで構成管理のベストプラクティスに従うことができ出来る
- Helmで管理すれば構成で困ることもないし、手動でたくさんマニフェスト(設定ファイル)を書く必要もな無い
- サーバーとアプリケーションの責任を明確に分離できる
- コンテナとしてアプリケーションを動かせるので責任境界がを明確になり、データ基盤チームとしてはアプリケーションをコンテナで動かせることだけに集中すれば良くなる見込みだった
- インフラもAirflowについて細かく知らなくても大丈夫になる

解決案の実装
方針が決まったので、実装しました。
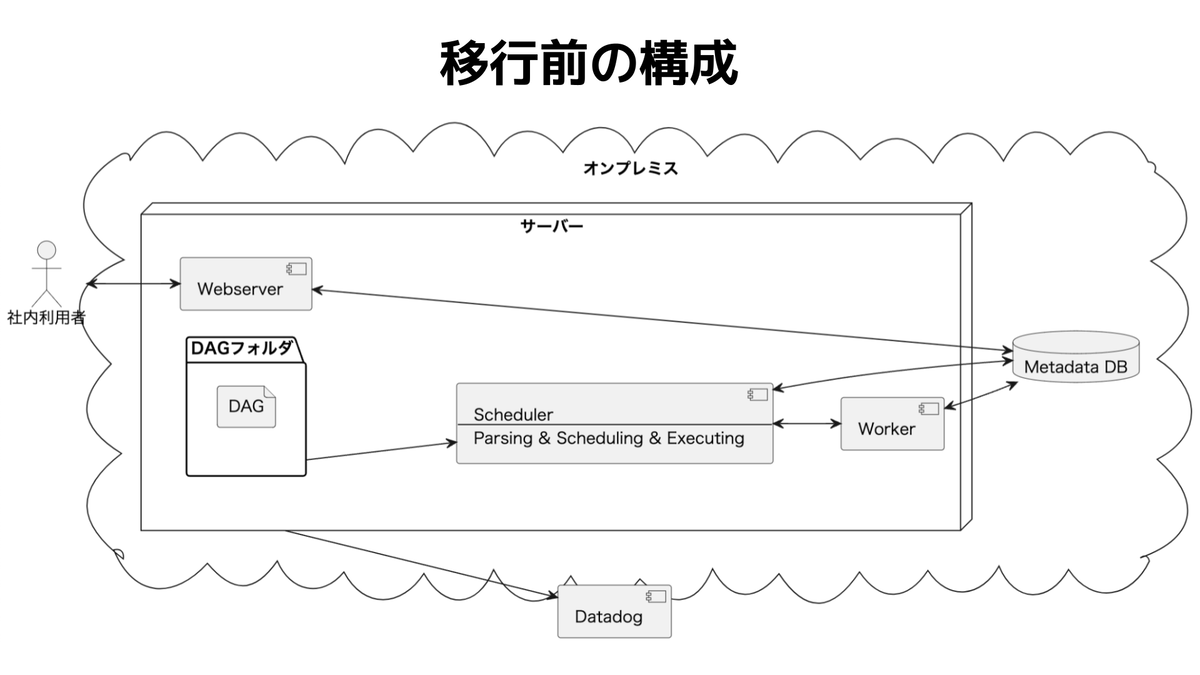
インフラの設定はAirflow公式が出しているHelm Chartsを入れてテンプレートの値を調整しています。 ExecutorはCeleryExecutorを採用して、タスクはKubernetesPodOperatorで動かすように強制しています。(SensorやEmptyOperatorなどは使っていますが、バッチ処理はKubernetesPodOperatorのみ使っています)

作り込む上で気をつけたことは、以下の3つです
- Airflowへの責務をスケジューラーに限定する
- チームAの処理がチームBの処理に影響を出さないようにする
- 利用者フレンドリーを意識する
Airflowへの責務をスケジューラーに限定する
AirflowにはシンプルなPythonOperatorから、より特定の用途に特化したBigQueryOperatorなど様々なOperatorが存在します。
特定の用途に沿ったOperatorを使うことで車輪の再開発を防ぐという考え方もあると思うのですが、これを採用することでスケジューリングとタスクが密結合になり移行しづらくなることを危惧してAirflowへの責務をスケジューラーに限定するように作っています。
AirflowはDAGで定義された時間に、DAGで定義された順番通りにbashコマンドでタスクを実行する(KubernetesPodOperatorを立ち上げる)だけに留めています。 bashコマンドで動かす実体はpythonスクリプトですが、Airflowとは全く別の依存関係を管理しています。
こうして分離することで、以下のようなメリットを感じています
- 仮に、別のオーケストレーション・スケジューリングツールに移行する場合に移行しやすい
- Airflow公式のベストプラクティス で言及されている、Airflowというアプリケーションを動かす依存関係と、タスクの依存関係の分離を行うことでバージョン管理がやりやすくなる
チームAの処理がチームBの処理に影響を出さないようにする
ピクシブのAirflowはマルチテナントです。そのためタスクのアイソレーションを適切に行わないと、チームAのタスクが原因で、関係のないチームBに影響が出ます。
私たちが工夫した点は以下の2つです。
- 1つのタスクに1つのPodを割り当てる
- 他タスクのリソース消費の影響を受けない
- チームごとにpoolを作り、pool内で優先順位を管理して貰う
- Airflowのスケジュール制約を回避する
一つ目はシンプルで、タスクごとに1つのKuberentesPodOperatorを割り当てる実装になっています。 もう一つの「チームごとにpoolを作り、pool内で優先順位を管理して貰う」について、もう少し詳しく解説します。
Airflowにはいくつもの同時実行数の制約が存在しています。
- Airflow全体で動かせるタスク(task instance)の同時実行数
- スケジューラーで動かせるタスクの同時実行数
- 1つのDAG内で動かせるタスクの同時実行数
- poolによる任意の同時実行数
k8sクラスタへの負荷を抑えるために、単にAirflow全体で動かせるタスクの同時実行数だけ制御すると、SLAの高いタスクが期待した時間通りにタスクがスケジュールされず遅延することが想定されました。
これらを解決するために、チームやプロダクトごとに事前にpoolと呼ばれる任意の同時実行数を割り当て、このpoolの範囲内であれば自由にタスクの優先順位を変えて、必ずタスクが時間通りに動くことを保証するようにしました。(Airflow全体の同時実行数はpoolの合計値を設定しています)
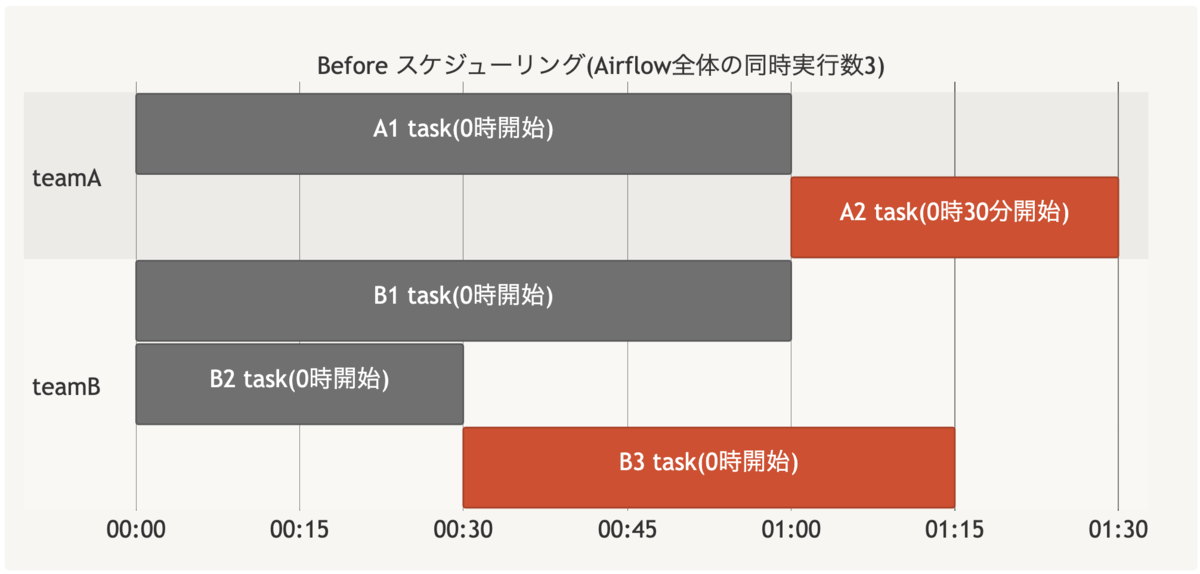
Before:
全体の同時実行数の制約により、意図せずにタスクの開始が遅延している。
(赤いブロックが意図せずにタスクの開始が遅延している部分です)
After:
設定した時間通りに動いていないタスク(B1)もあるが、これは優先度が低いと各チームで各自で判断したもののため期待通りの挙動。
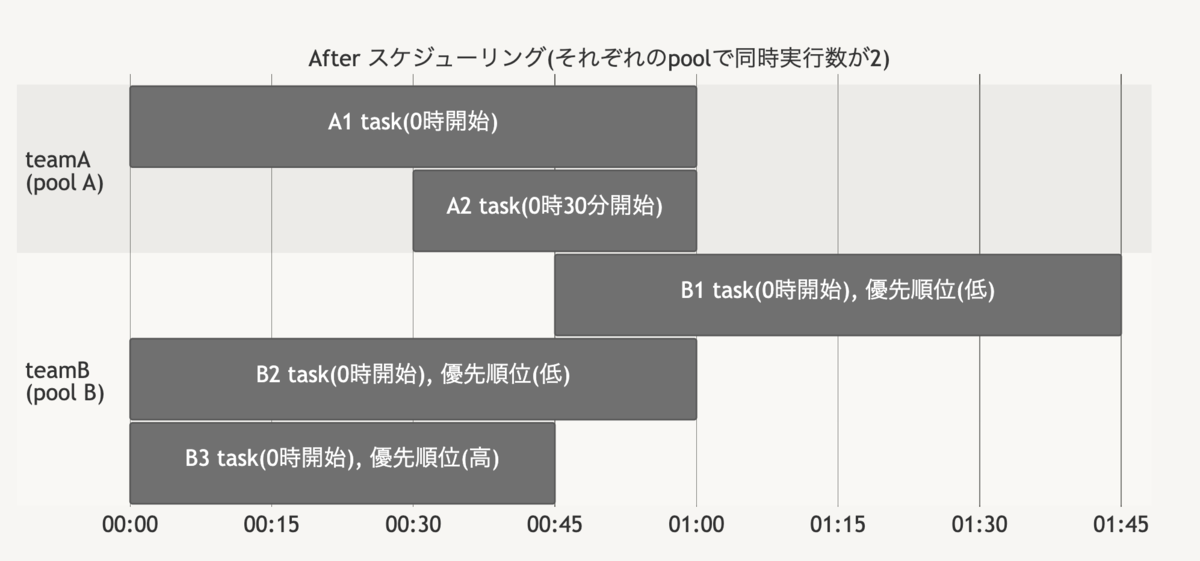
利用者フレンドリーを意識する
「はじめに」のセクションでも述べたように、ピクシブのAirflow利用者は大半がデータを専門としないエンジニアです。そのため、実装時の認知負荷を抑えることを強く意識しています。
具体的には以下のような仕組みを導入しています。
- 生のAirflowのオブジェクトは触らないで良いようにする(ラップした処理を使って貰うようにする)
- 事前に設定した方が良い共通の項目はラップした処理で設定する
- 開始時間
- catchupの設定
- DAG名・DAGのフォルダなどのバリデーションもここに集約して、問題があれば DAG Loaderテスト でエラーが出るようにする
- 事前に設定した方が良い共通の項目はラップした処理で設定する
- 絶対に設定して欲しい項目が設定されていなければCIでエラーを出す
- mypyも併用することで期待した入力になっているかを検証
ラッパーのサンプル
from airflow.models.dag import DAG class AirflowDag(DAG): def __init__( self, dag_id: str, pool: PoolTemplate, schedule_interval: str | None, ): self.dag_id = dag_id self.validate_dag_id() super().__init__(..) def validate_dag_id(): if not dag_id.startswith("bq-"): raise Exception("名前がbqから始まっていません")
呼び出し側のサンプル
from airflow_dags.common.dag.airflow_dag import AirflowDag from airflow_dags.common.pools.list import PoolList from airflow_dags.common.task.factory import TaskFactory # Airflowを使う時には全社的に共通で設定したい項目があるので、 # このAirflowDagというラッパーを使う dag = AirflowDag( dag_id="test-run-bq-batch", # ファイル名と同じ pool=PoolList.DATA_PLATFORM_POOL, schedule_interval="0 12 * * *", # cron形式 ... ) # このtask_factoryというやつにTemplateタスクが集約されている task_factory = TaskFactory(dag=dag) # 最も一般的な処理(check -> bqのtransform) ( task_factory.check_updated(table_path="hoge.fuga") >> task_factory.run_bq_batch_updates(table_path="example.update"), )
※ コードは適当に改変して作っています
移行した結果
解決した課題
構成を変えたことで、当初の課題が全て解消されたのは良かったです。
- リソース不足が原因だと思われる謎のスケジューラー停止が定期的に起こる
- CPU不足によるタスクの遅延
- インフラがサーバーを管理して、データ基盤チームがAirflowというアプリケーションを運用しているのでサーバー関連のトラブルシューティングしづらい
- スケールアウトできない
また移行を進めていく上で実装を工夫したことで、以下の課題も解決できました。
- Airflowの依存関係とバッチ(タスク)の依存関係が分離していないので、バッチのライブラリアップデートがAirflowのバージョンアップ待ちになる
- チームAのタスクが問題でチームBのタスクが遅延する
新しく出た課題
逆に構成を変えたことで以下のような問題が出ています。 これらについても少しずつ解決して、より利用者が便利な環境を作っていきます。
- デプロイにかかる時間が長い (=コンテナのビルド時間が長い)
- DAGリポジトリと、バッチリポジトリを分割したことで2回MRを作る必要があるのが手間
k8sでAirflowを運用してみての感想

環境要因が大きく、全ての企業で通用するとは思いませんが、個人的には思ったより簡単だと感じています。 k8s特有の辛さは共通のk8sクラスタに乗ればだいぶ軽減できています。
周りにk8sに詳しい人がいない、k8sが会社としてあまり採用されていない技術スタックである等の場合にはAirflowのためだけに採用するのはオーバーエンジニアリングすぎる印象を持ちました。

k8s周りで学習すべき所が多いのは明確にデメリットだと感じています。 属人性が高くならないようにチーム内で教育が必要だったり、採用のハードルが高くなる等が想定されます。 また共用のk8sクラスタに乗る都合でいくつか制約がありました。

共用のクラスタには本番のエンドユーザー向けのプロダクトも乗っています。 バッチの特性上、Airflowの処理は特定の時間に負荷が集まるので、そのまま移行すると他サービスに影響を与えてしまう可能性がありました。 そのため、移行時にはスケジュールを平滑化しながら少しずつ移行しました。 この移行作業が一番辛かったです。


おわりに
ピクシブではAirflowをk8sで運用することは思ったより簡単でした。
何か少しでも皆様のご参考になれば幸いです。 最後までご覧いただきありがとうございました。


