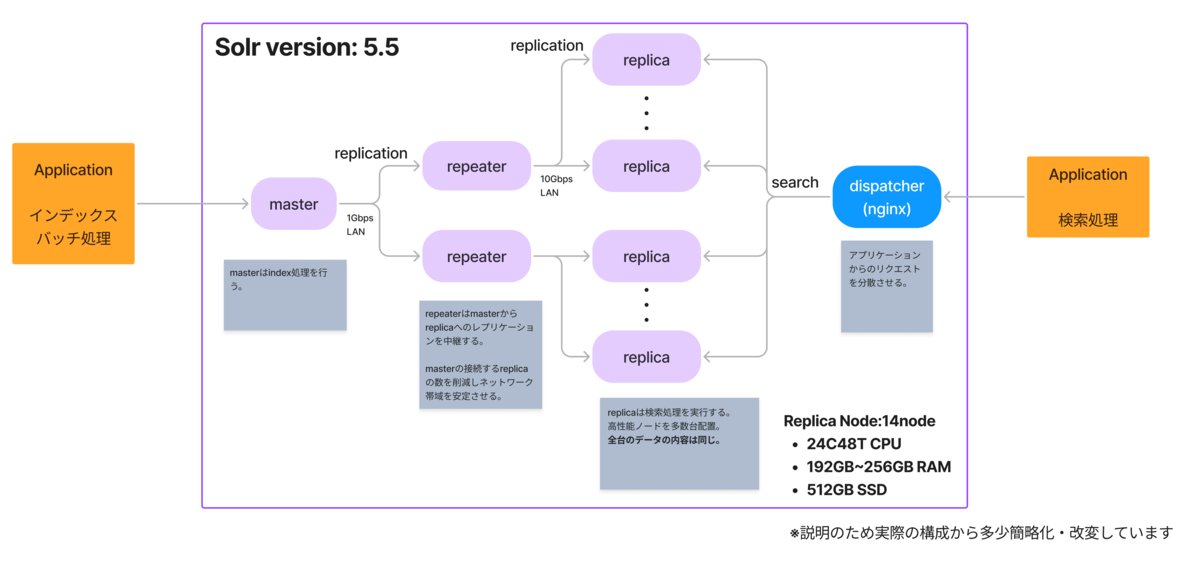
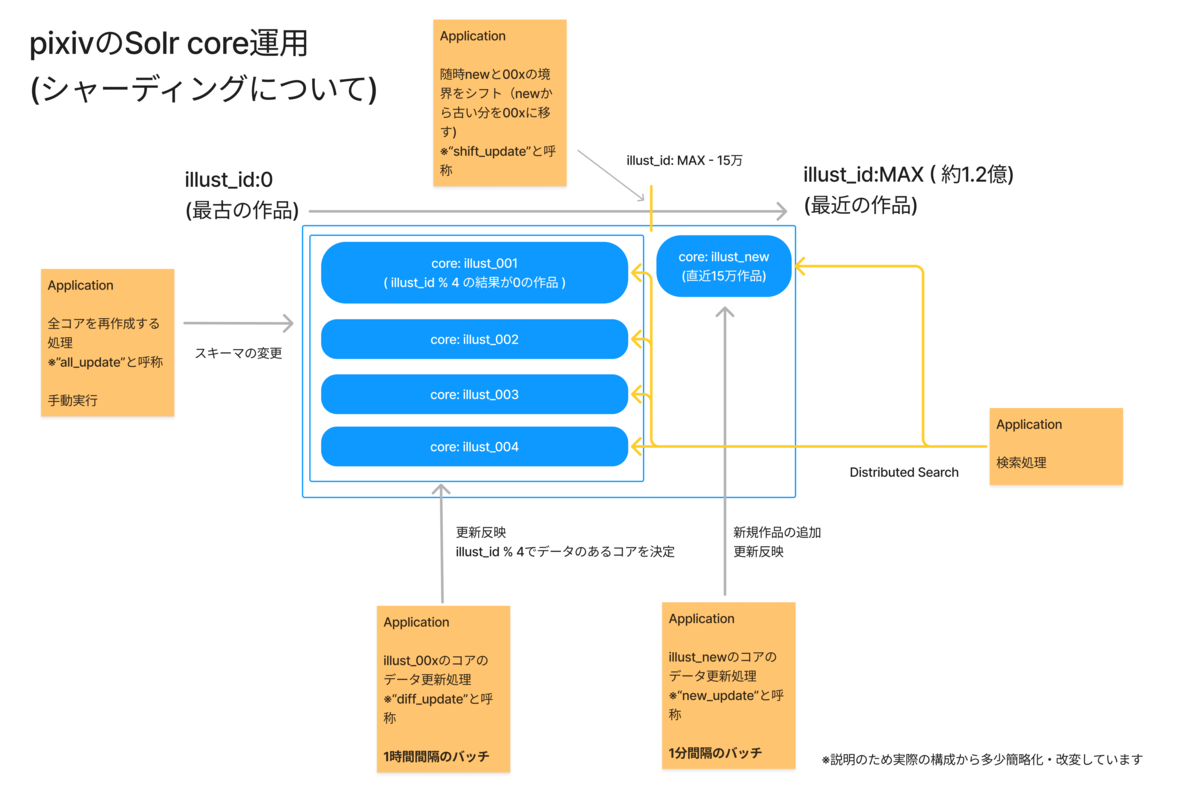
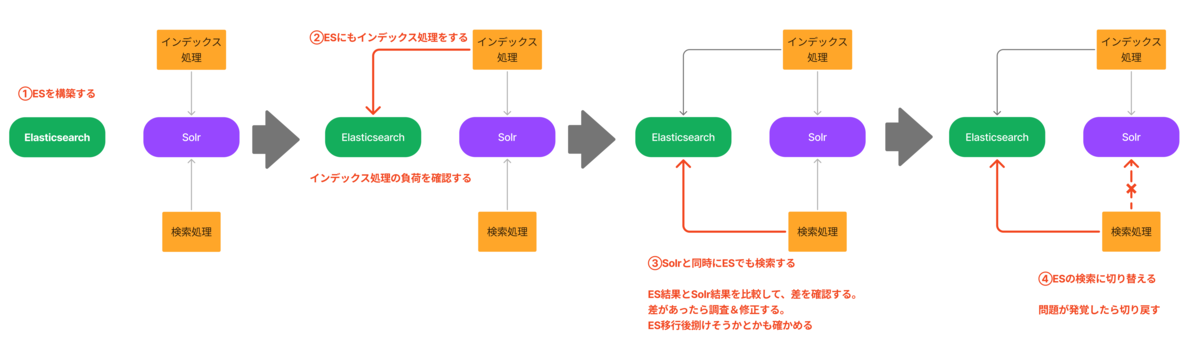
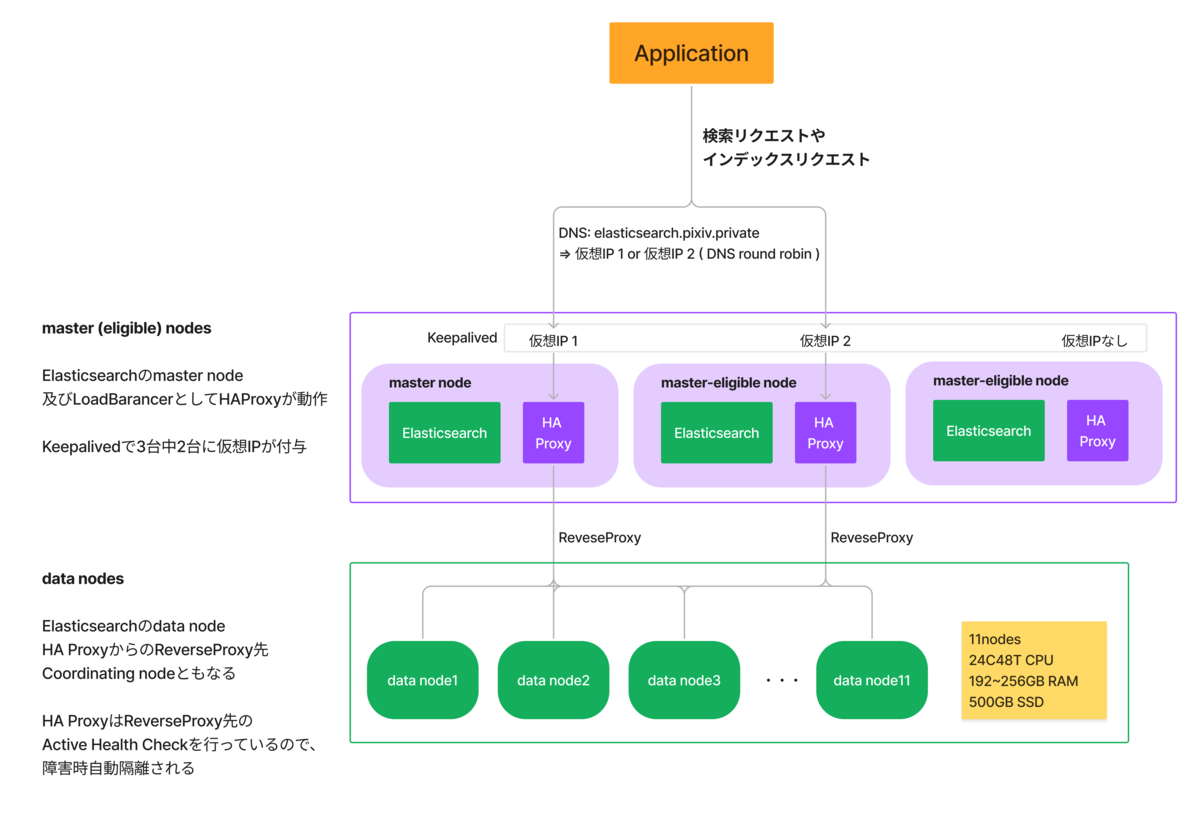
2025年8月27日、pixivに新しくコレクション機能(β版)がリリースされました。
pixivに投稿された作品や、pixiv関連サービス(ピクシブ百科事典、BOOTH、pixivFANBOXなど)、外部ウェブサイトのURLをpixiv上にまとめて公開できる機能です。
コレクション機能(β版)は、ユーザーが自身の「好き」を表現し、より多くの人に届けられるようにするために作られました。これを実現するためには、ユーザーが作品やテキスト、リンクなどの要素を直感的に操作して魅力的な配置を作れる必要があります。
いくつかのデザインを検討した末に、要素をタイル状に並べる、いわゆる Bento Grid デザインを採用することにしました。
 本記事では、コレクション機能(β版)の一部であるコレクション作成画面の開発について、その技術的な背景を紹介します。
本記事では、コレクション機能(β版)の一部であるコレクション作成画面の開発について、その技術的な背景を紹介します。
こんにちは、pixivの開発をしているytoです。
コレクションの作成画面では、直感的なタイル操作を実現するため、ドラッグ & ドロップでタイルを移動・変形できるような UI が実装されています。
このタイル編集 UI は、以下の要件を満たす必要がありました。
- 各タイルはドラッグ & ドロップで移動・変形ができる
- 移動できる位置・変形後に取りうるサイズは連続的ではなく離散的で、grid-snap が効く
- タイル同士は重なってはいけない
- 移動・変形後に上方向にスペースが空いた場合、その下にあるタイルは上方向に強制的に詰められる(上方向の重力がある)。左右方向のスペースが詰められることはない(左右方向に重力はない)。
これを実現したプロトタイプ実装の挙動がこんな感じになります。

今回は、このプロトタイプができるまでの話をします。
ドラッグ & ドロップでタイルを移動・変形するUIの実装
正方形グリッドの敷き詰め
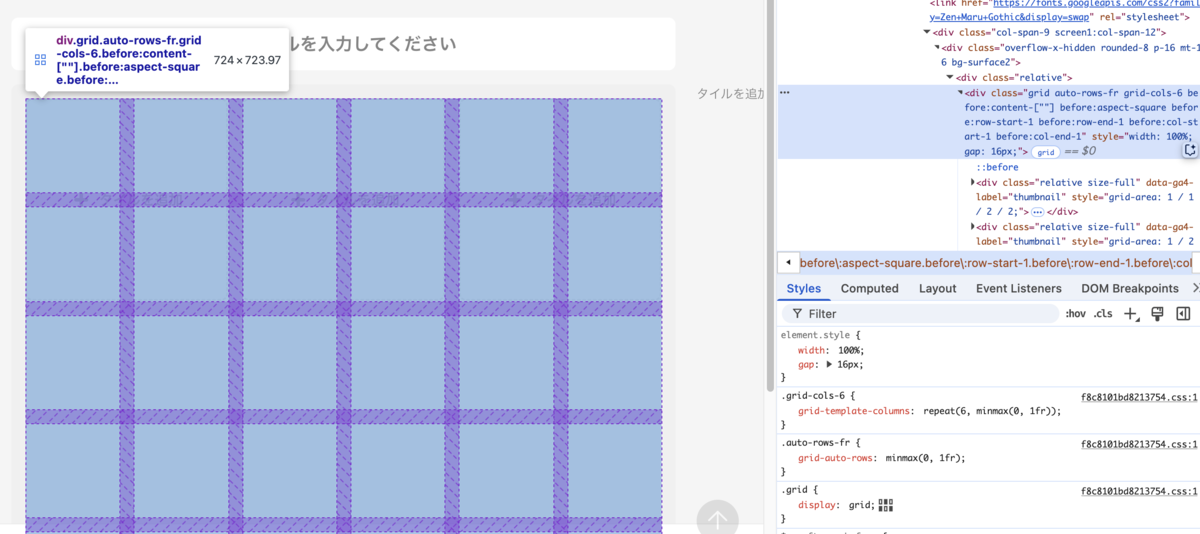
CSS Grid Layout を利用して横6列のグリッドを表現します。このグリッドがタイル移動・変形時の単位として使われます。
グリッドを敷き詰めるコンテナのサイズは、画面幅に応じて変わります。
横幅は grid-template-columns: repeat(6, 1fr) 指定をすれば1/6サイズに分割したグリッドを得ることが容易にできます。
この横幅と同じ長さを1とする縦方向のサイズ指定は、ちょっとしたテクニックが必要でした。
grid-auto-rows: 1frを指定- グリッド内の最初の要素の位置に、高さを指定するための aspect-ratio: 1 の before 要素を配置
これによって、サイズ指定のためだけのダミー要素を大量に追加したり、 JavaScript でサイズ計算をしたりすることなく、CSSだけで実現することができます。
参考: html - How to make div height equal to width in CSS Grid - Stack Overflow
タイル移動の実装
ドラッグ & ドロップでタイルを移動する基本的な実装は、 dnd-kit を利用しています。
既存のコードベース内で dnd-kit/core および dnd-kit/sortable を利用していたことが採用理由として大きいですが、今回のタイル編集画面の実装にあたってはその拡張性の高さに助けられる場面が多くありました。
dnd-kit の詳しい使い方については割愛しますが、以下の2つの概念が登場します。
- Draggable: ドラッグしたい要素
- Droppable: ドロップ先の要素
Draggable な要素はマウス操作などで動かすことができ、マウスを離した時(ドロップ時)に発火するイベントから、それがどの Droppable の上にあるかなどの情報を得ることができます。
dnd-kit の提供する useDraggable() や useDroppable() が返す ref を DOM に渡すことで、どの要素をDraggable/Droppableにするかを指定します。
今回実装したタイル編集 UI では、横6列のグリッド上のどの座標にドラッグされたかを知りたいので、以下のような方針で実装しました。
- タイルはそれぞれが自身の位置の情報を持っており、外側にいるタイル編集 UI はコレクション内に含まれるすべてのタイル情報の配列を持つ
- 横6列のグリッド上に透明な Droppable を敷き詰め、それぞれの Droppable に対して自身の座標(何列目の何行目にいるのか)を持たせる
- タイルそれぞれを Draggable とする
この状態で、タイルがドラッグ & ドロップされる際、ドロップ時にどの Droppable の上にいるか(=どの位置に移動するか)が分かります。その情報を使ってコレクション全体の新しいタイル配置を再計算し、画面上に反映させることでタイル移動が実現できます。
dnd-kit が介入するのはドラッグ & ドロップ処理が完了するまでで、ドロップ後の再配置の計算とUIの更新はコンポーネント側が行います。
// タイル編集 UI 全体の管理 function DndTileEditor({ tiles, /** .... */ }: Props) { const handleDragEnd = useCallback(() => { // タイル移動後の位置の再計算 }, []) return ( <DndContext id='collectionTileEditor' onDragEnd={handleDragEnd} > <div> {/* Droppable を並べる */} <DroppableLayout rows={droppableRows} /> {/* コレクション内のタイルを並べる */} <TileLayout items={tiles} factory={(tile: TileData) => <DraggableTile tile={tile} />} /> </div> </DndContext> ) }
// Droppable の敷き詰め function DroppableLayout({ rows }) { // 略 // rows の分だけ [{x: 0, y: 0}, {x: 1, y: 0}, {x: 2, y: 0}, ..., {x: 5, y: 5}] のような配列を用意して DroppableTile を並べる return positions.map((position, index) => <DroppableTile key={index} position={position} />) } function DroppableTile({ position }) { // 自身の座標を data として持つ const { setNodeRef } = useDroppable({ id: `droppable-${position.x}-${position.y}`, data: { position }, }) return ( <div ref={setNodeRef} style={{ /** position を参照して grid-column-start 等の位置・サイズを指定するスタイルがつく */ }} /> ) }
// Draggable なタイル /** * 移動・変形が可能なタイル */ function DraggableTile({ tile }) { const { attributes, listeners, setNodeRef } = useDraggable({ id, data }) return ( <DraggableContainer id={tile.id} ref={setNodeRef} {...listeners} {...attributes} > // タイルの中身 </DraggableContainer> ) })
タイル変形の実装
タイルのサイズ変形も dnd-kit のみで実装しています。
- タイルの周辺に表示するサイズ変形用の「つまみ」を Draggable として扱う
- Droppable はタイル移動処理に使われているものと同じ
タイル移動処理と同様に、ユーザーがつまみをドラッグ & ドロップした際にドロップ時の位置を取得し、変形後のタイルのサイズを計算することができます。
これもタイル移動処理と同様に、 dnd-kit が介入するのはつまみのドラッグ & ドロップが完了するまでで、その後のタイルサイズの計算と描画はコンポーネント側で行います。
上方向の重力と衝突回避(Masonry Layout)の実現
ここが最も困難だったポイントです。
タイル同士が重ならないようにし、かつ上方向にスペースができたら自動で詰める、という要件を満たす必要がありました。
このようなレイアウトは Masonry(組積) Layout と呼ばれ、 Firefox など一部のブラウザには実験的な機能として CSS グリッドレイアウトの一部に組み込まれています。
これを実現するための方法として、主に以下の2つのやり方を検討しました。
dnd-kitのsortableを活用する- すでに導入している
dnd-kitで完結できるのは魅力的でした。しかし、sortableのデモなどを確認すると、要素を並べ替える一方向のソートが基本で、今回の要件である「空いたスペースに上から詰める」という挙動とは異なりました。自前で複雑な計算ロジックを追加する必要がありそうだと判断し、採用を見送りました。
- すでに導入している
- react-grid-layout を使う
- このライブラリのデモが、移動、変形、衝突回避、重力といった要件をほぼ満たす理想的な挙動でした。
- しかし、2025年10月現在でも React 18 への完全な互換性が保証されておらず、コンポーネントとしてそのまま利用すると意図しない挙動を引き起こす可能性がありました。
- また、 dnd-kit を用いたタイル移動・変形の処理がすでにあったため、ドラッグ & ドロップの UI 側の処理まで担うコンポーネントライブラリは too much でした。
(参考)その他参考にしたライブラリ・実装・issueなど:
- Composition of DND with List Components? · Issue #944 · clauderic/dnd-kit
- Responsive mosaic/grid in ReactJS with Drag and Drop support
- Masonry
- Packery
react-grid-layout の計算ロジックと dnd-kit を組み合わせる
react-grid-layout の挙動は理想的ですが、互換性のリスクは避けたく、またドラッグ & ドロップ処理の部分は不要でした。
ありがたいことに、このライブラリはレイアウト計算に関するロジックを個別の関数で提供しています。
そこで、dnd-kit で実装したドラッグ&ドロップの仕組みはそのままに、ドロップ後のタイル配置計算部分だけを react-grid-layout のロジックに任せる、という方針を採りました。
前述したように、タイルの移動・変形が行われた際、 dnd-kit の onDragEnd() イベントが発火したタイミングでコレクション全体のタイル配置を再計算しています。
このタイル配置の計算に react-grid-layout のユーティリティ関数を組み込み、衝突回避と上方向の重力の適用を実現しました。
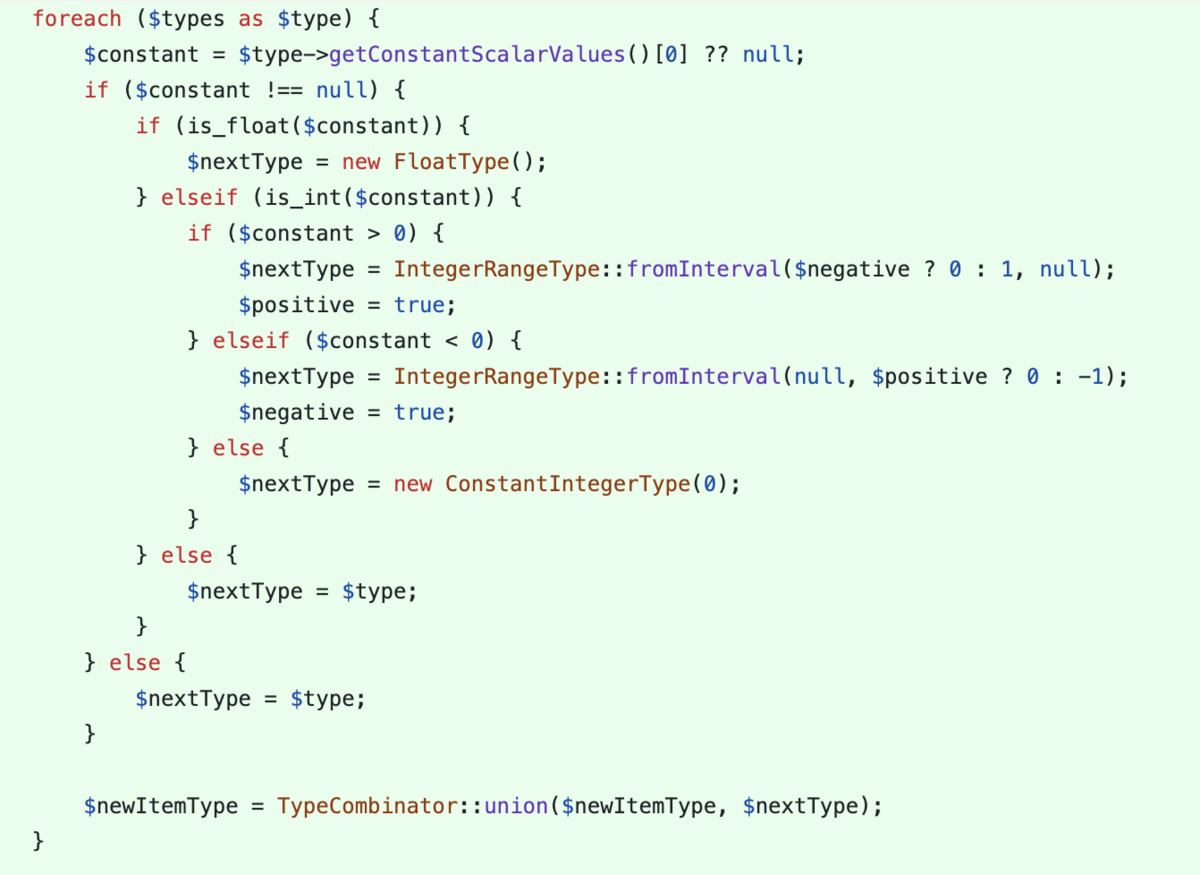
import { LayoutItem, utils } from 'react-grid-layout' /** * コレクションのタイルデータを react-grid-layout で扱う Layout 型に変換する */ function tileToLayout(tile: TileBaseData): LayoutItem { const { size, position } = tile.layout return { i: tile.id, x: position.x, y: position.y, w: size.x, h: size.y, moved: false } } /** * react-grid-layout のロジックを使って、タイル移動時のタイル同士の衝突回避・上方向に詰める重力を適用したレイアウトを返す */ function moveAndCompact( { tiles, activeTileId, moveTo, cols }: { tiles: TileData[]; activeTileId: TileData['id']; moveTo: { x: number; y: number }; cols: number;} ): readonly LayoutItem[] { // 型変換などの準備 const layouts = tiles.map(tileToLayout) const activeTileLayout = layouts.find(layout => layout.i === activeTileId) if (!activeTileLayout) { return [] } // react-grid-layout のロジックを使って、衝突回避を適用したレイアウトを計算 const movedLayout = utils.moveElement( layouts, activeTileLayout, moveTo.x, moveTo.y, true, // isUserAction (ユーザー操作による移動なので true ) false, // preventCollision (衝突を許容したいので false ) 'vertical', // compactType (どの方向に重力が働くか) cols, false // allowOverlap (タイル同士の重なりは許容しないので false ) ) // react-grid-layout のロジックを使って、上方向の重力を適用したレイアウトを計算 const compactedLayout = utils.compact(movedLayout, 'vertical', cols) return compactedLayout }
ソースコードを確認すると、コレクション内のタイルの数をNとしたとき、 utils.compact() の最悪の計算量は O(N2) となります。これは現代の一般的な端末であればN=50程度までならほぼ体感の遅延なく操作が可能で、100〜150程度までなら許容できる程度の遅延におさまります。
また、この計算処理はドラッグ操作中に連続的に行われるのではなく、離散的なグリッドの上での onDragEnd や onDragOver が発火したタイミングで実行されるため、操作がもたつくようなこともなく全体としてスムーズな動作を提供できます。
実際にリリース後のフィードバックを見ていても、タイル操作が重いといった声は特に見かけませんでした。
おわりに
以上のように、要件を満たすタイル編集UIのプロトタイプを実装することができました。
dnd-kit が提供する柔軟なAPIをベースに、タイルの配置ロジックをコンポーネント側に実装することで、プロダクト的に要求される仕様を妥協なく実現できたと思います。
リリースまでの間にたくさんの機能追加やデザイン改善が行われ、実際のコレクション作成画面の UI はよりリッチになっていますが、ベースとなるタイル移動・変形処理はこの時に作ったロジックが使われています。
コレクションの作成機能は、現在は一部のユーザーから少しずつ開放しています。
コレクションを作ってみたい方は、ぜひ以下のページから「作ってみたい」ボタンより応募ください。