

Introduction
Hi, my name is yue, from the VRoid team.
We recently rewrote our 3D model distributing server in Rust and adopted Zstandard (zstd) as the compression format.
As a result, the following changes occurred compared to the original Node.js server:
- The max response time decreased from
1.5 - 2.5sto300 - 400ms. - The average response time decreased from
700 - 800msto150 - 200ms. - CPU usage decreased from
50%to10%crica. - The size of the Docker image decreased from
346mbto21mb. - The model files sent to clients are now
10 - 20%lighter on average compared to before.
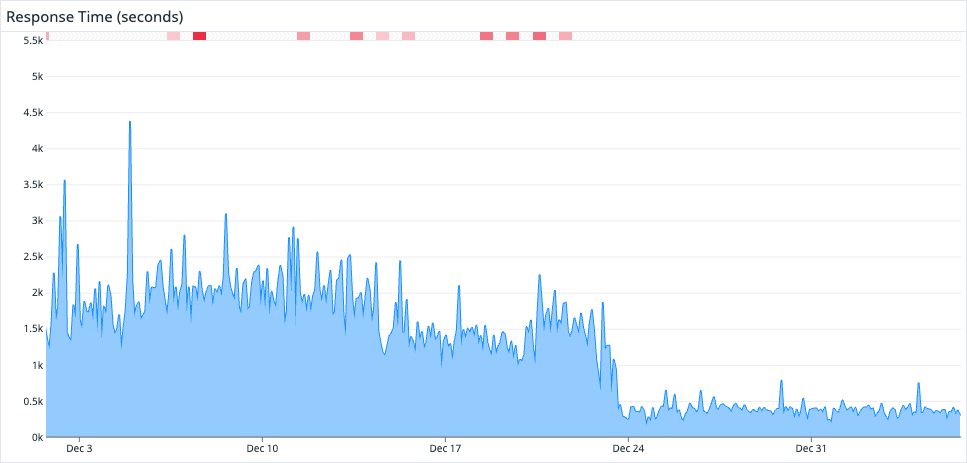

We didn’t find a significant difference in terms of memory usage except that it became more stable, which may be mostly due to two reasons: the fact that we have to load full model data into memory, and the implementation of the allocator. There are reports about how switching the allocator to jemalloc or mimalloc would improve this issue, however, since it is not causing any problems in the production environment, we consider this behavior to be acceptable and did not go forward in making the switch.

In the upcoming paragraphs, I will discuss the technical challenges involved, provide reasons for our selection of Rust and zstd, and finally give some details about how we prepared the release.
Challenges in distributing VRM/glTF files
The humanoid 3D models handled in VRoid Hub are based on a format called VRM, which is built on the glTF format. While glTF is optimized for runtime use, there are various challenges when considering distributing it as a service.
Compression Formats for Transporting
In order to secure content protection on VRoid Hub, model files are edited and encrypted on demand. Since compression via content-encoding is less effective after encryption, we have to select a compression format.
After profiling the existing Node.js server, we found that gzip/gunzip for model files of several tens of MB incurred significant execution costs.
There are various mainstream compression formats, such as gzip / zstd / lz4 / xz, each with its own performance characteristics.
gzip/zstd: General purposelz4: Low compression ratio, high processing speed / Real-time usexz: High compression ratio, low processing speed / Archive use
Another option would be google/draco, which is specialized in compressing 3D data. However, we could not confirm clear benefits when we considered using it in the past, so we decided not to look into it any further for the time being.
In order to distribute model files, it is necessary to consider compression ratio and overall resource usage on both the client and server side. Among the general-purpose gzip / zstd, we conducted further investigation at the implementation level. There are also multi-threaded options such as pigz / zstdmt, but we have various concerns regarding how they operate on the server side, so we excluded them from consideration this time.
Server Side
The standard zlib is the most commonly used implementation of gzip. However, in recent years, there have been efforts to improve performance such as forks like zlib-ng and cloudflare/zlib due to the CPU-bound nature of the compression process.
zlib-ng has been used in projects like deno, and recently the Fedora distro of Linux started considering replacing the standard zlib with zlib-ng, as mentioned here.
In actual tests with sample data, the compression ratio of zlib-ng with default settings was lower than that of the standard zlib. Furthermore, when adjusting the settings to achieve similar compression ratios, the processing load becomes similar as well. There was not a significant difference observed between zlib-ng and cloudflare/zlib.
Although zstd is a relatively new format, it can be used via the Basis Universal texture format and it has been confirmed to reduce processing time and cost by approximately 3 to 4 times while maintaining compression ratio.


Client Side
The performance of compression has two ends, including both server-side compression and client-side decompression.
At VRoid Hub, we have transitioned to using the DecompressionStream API along with fallback to zlib browserify since 2022. With the adoption of zstd on the server side, we are using a wasm decoder on the client side. While zstd's decompression is superior to gzip at the algorithm level, the results from test data show that it almost matches the performance of the native DecompressionStream. Considering the reduction in transfer size, we think there are benefits on the client side as well.
The adoption of zstd is also progressing on the browser side, with support for zstd in Content-Encoding starting from Chrome 118, and there are also efforts to support the DecompressionStream API.

From the perspective of compression, decompression, and resource usage, there are significant advantages to adopting zstd, and we feel that there will be an increasing number of cases where zstd gets chosen over gzip when the client has decoding support.
Encryption
Encryption is critical in processing and can have significant performance differences depending on the implementation. Here, we mainly focused on comparing openssl, Golang’s standard libraries and RustCrypto. We found that both openssl and Golang’s standard libraries, which are written in assembly language for each platform, outperform RustCrypto.
Additionally, the presence of certain compiler flags also has a significant impact in this field. For example, enabling ARMv8 Crypto Extensions by adding RUSTFLAGS="--cfg aes_armv8" for ARM, or utilizing the AES-NI instruction set on x86 can help avoiding side-channel attacks. aws-lc-rs is also an option, but we are still in the process of evaluating it.
Modifying VRM / glTF
In order to modify glTF, we compared glTF Transform, gltf-rs/gltf and qmuntal/gltf. Although glTF Transform is the most feature-rich and high-quality tool in the industry, it requires heavy testing for our use case according to its scale. qmuntal/gltf is being used in the industry for similar purposes, but when tested with real data, it failed to meet our requirements without significant customization. gltf-rs/gltf is used in game engines, but it had limited APIs for editing, so we ended up using it only partially, like the importer/exporter and serializers.
Why Rust
At pixiv Inc., each team has the freedom to choose their own tech stack. While Rust and zstd have already been used internally in several places, this is the first time Rust has been adopted as a user-facing server-side language.
For this replacement, we conducted prototyping in TypeScript, Rust, and Golang, and finally decided on Rust primarily for the following reasons:
Performances
Since we are fetching and sending model files while performing compression and encryption, this server is both I/O-bound and CPU-bound by its nature. An async runtime like tokio will help with the I/O part. Although zlib / zstd / openssl bindings are used in some form for compression and encryption regardless of the language, the performance difference at the language level is reflected in the final response time and resource usage. By adopting Rust, we will be able to consider parallelization of processing.
Control and Correctness
When editing VRM files, operations like manipulating binary buffers frequently occur. Therefore, languages like Rust, which offer lower-level control, are more suitable for this task. At the same time, Rust focuses on correctness. At the language level, Rust guarantees memory safety and forbids implicit type conversion. These features enable us to identify and resolve several existing bugs during migration.
Compatibility with Other Processing Needs
At VRoid Hub, we also optimize models at the time of uploading: a process we are now trying to revamp. Rust felt like the right candidate for migrating from the existing Unity-based CLI tool. Additionally, there is the possibility of providing bindings to other languages in the future or embedding it as wasm into the front end.
Adoption Range of Libraries
Rust has various libraries built for game engines, browsers, and other development purposes, which synergize with what we want to achieve. The choice of compression libraries is not limited to the standard zlib. In comparison to Node.js, there is also mongodb-js/zstd, but it’s Rust code wrapped with an additional layer via napi, whereas we wanted to directly adopt zstd-rs instead of increasing the dependency layer.
Team Members' Skills
In terms of languages itself, TypeScript, Rust, and Golang each have their own merits among the choices. However, in our team, there were more members familiar with Rust than Golang, so it came down to a choice between TypeScript and Rust. Furthermore, there is a cross-functional Rust community within the company that we can consult, so there were fewer obstacles to adoption.
Preparation for Production Deployment of Rust
Build Setup
Taking into consideration the existing ecosystem and ease of operation, we built the server upon tokio and axum with AWS SDK for Rust. For production builds, we have chosen distroless/cc as the base docker image considering compatibility with crypto libraries.
CI / build cache
Since the compilation time of Rust is significantly longer than Golang, CI / build cache was crucial. In fact, the build speed was sufficient when we tried caching $CARGO_HOME and target in GitLab. It takes about 20 seconds to complete the build as long as the dependencies do not change.
.gitlab-ci.yml sample
variables: CACHE_VERSION: v1 CARGO_HOME: $CI_PROJECT_DIR/.cargo FF_USE_FASTZIP: "true" .build_cache: &build_cache cache: key: files: - Cargo.lock prefix: ${CACHE_VERSION}-build paths: - .cargo - target policy: pull-push
Migration and Monitoring
Sentry is used as an internal error monitoring tool across our infrastructure, and this time we have introduced Sentry SDK for Rust.
Since the panics within the worker are not sent to Sentry, we are using tower_http::catch_panic.
fn app() -> Router { Router::new() .route("/", ...) // ... .layer(CatchPanicLayer::custom(handle_panic)) // ... } // https://docs.rs/tower-http/latest/tower_http/catch_panic/index.html#example fn handle_panic(err: Box<dyn Any + Send + 'static>) -> Response { let details = if let Some(s) = err.downcast_ref::<String>() { s.as_str() } else if let Some(s) = err.downcast_ref::<&str>() { s } else { "Unknown panic message" }; sentry::capture_message(details, sentry::Level::Error); ( StatusCode::INTERNAL_SERVER_ERROR, Json(json!({ "message": "internal server panic" })), ) .into_response() }
We also use Sentry's performance monitoring. By adding #[tracing::instrument], the corresponding metrics are automatically sent to Sentry.
#[tracing::instrument] fn foo() { // ... }
As a note, the #[tracing::instrument] attribute records all default parameters to Sentry, so performance costs occur depending on the size of the parameters. To avoid this, it is recommended to use #[tracing::instrument(skip_all)] or #[tracing::instrument(skip(very_large_buffer, very_large_state))].
#[tracing::instrument(skip_all)] fn foo(very_large_buffer: Vec<u8>, very_large_state: LargeState) { // ... }
Conclusion
The migration to Rust and zstd this time was not a simple rewrite or replacement, but a redesign of the entire existing application while resolving several existing issues that were not listed in this article, resulting in significant performance improvements. We deeply appreciate the support and reviews received in the company internally for the release, and are grateful to everyone involved.
It was a lucky coincidence that both hyper and AWS SDK for Rust reached v1 around the time of our release. We are looking forward to contributing back to OSS projects and the ecosystem.
We will continue to focus on improving our services.



