こんにちは、lyluckです。
ピクシブではオンプレミスKubernetes(以下、k8s)クラスターを運用しています。
既存アプリケーションのk8s移行は依然として進行中で、クラスターの規模は以前と比べて倍の20台程度になっています。
アプリケーションをk8s移行するには、アプリケーションログの転送機能も一緒にk8sへ移行する必要があります。
今回はk8sにおけるログ転送時のログ欠損を抑えるために取り組んだことを紹介します。
背景
k8s移行対象のアプリケーションには転送が必要なログを生み出すものがあります。
次の図のように、Fluentdがログをアプリケーションがあるサーバーとは別のサーバーへ転送しています。

左側のサーバーの中身すべてをk8sクラスター上で動かすにはFluentdもk8sクラスターへ移行する必要があります。
ログ転送のためのFluentd DaemonSetがあったのですが、運用面で課題がありました。
まとめ
ログ転送に使っているFluentd DaemonSetにはk8sクラスター更新時に正常終了できないという問題がありました。
この問題を解決するため、k0sctlへコントリビューションしました。v0.24.0でリリースされています。
詳細
Fluentd DaemonSetでログ転送する
DaemonSetとはk8sクラスターのすべてのワーカーノードで1つずつPodを起動させるワークロードのことです。
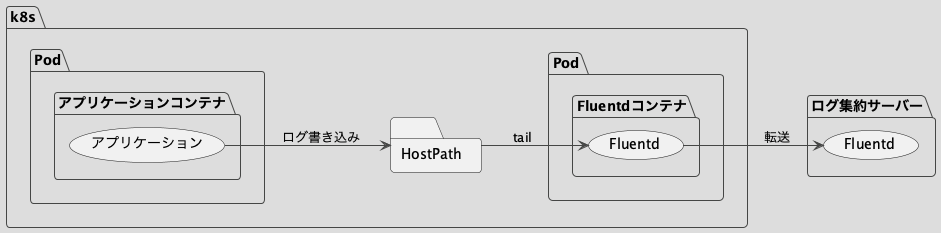
このようにHostPathにログを書き込ませ、Fluentdに転送させます。posファイルやfileバッファーもHostPathへ保存することで、Fluentd Podが再起動しても続きからログ転送を再開できます。
なぜHostPathを使うのか
管理が面倒になるからです。
localボリュームはノードごとに作成が必要です。それらに紐づくPersistentVolumeClaim(以下、pvc)もノードごとに必要になります。
そのような複数の名前の違うpvcを、Podの割り振られたノードごとに適切にマウントするようなDeploymentマニフェストは書けません。
たとえばアプリケーションをStatefulSetにするとアプリケーションのマウント問題は解決するかもしれませんが、結局Fluentd DaemonSetでも同じマウント問題が発生します。
k8sクラスターの更新時にFluentdを正常終了できない問題
k8sクラスターはk0sctlを使って管理しています。k8sクラスターのk0sのバージョンを更新する場合、ワーカーノードごとに次の処理が走ります。
- cordon: 新規Podがスケジュール不可にする
- drain: このノード上のPodを削除する
- k0s バージョンアップ: ワーカープロセスを再起動する
- uncordon: 新規Podをスケジュール可能にする
1の処理ではDaemonSetのPodはスケジュール不可になりません。2の処理ではDaemonSetのPodは削除されません。
Fluentd Podは生き続けたまま3の処理を迎えることになります。ログ転送処理中かもしれないFluentdがワーカーノードごといきなり消えるかもしれないということです。たとえfileバッファーを使っていても、Fluentdプロセスがクラッシュする場合はログ欠損する可能性が残ります。
Fluentd DaemonSetをどうやって正常終了させるか
2通り考えました。
- クラスター更新時にはすべてのログ転送を止める
- k0s更新のタイミングにフックを追加する
1. クラスター更新時にはすべてのログ転送を止める
クラスター更新処理を開始する前にログ転送を停止し、更新完了したら開始します。
ログ転送停止は、例えばFluentd DaemonSetのcommandをsleepのような何もしない処理に差し替えれば可能です。既存のPodは正常終了し、何もしないPodに入れ替わります。
しかしこのやり方ではログの遅延が大きいです。ノード一つ一つの更新処理は数分程度なのですが、クラスター全体だと数十分かかります。
2. k0s更新のタイミングにフックを追加する
ノードごとに更新が開始したタイミングでログ転送を停止し、そのノードが更新完了したら開始します。
アプリケーションPodもノードの更新開始時に削除されるので、ログの遅延は小さいはずです。
しかしこれは不可能でした。k0sctl v0.23.0ではクラスター更新の開始と完了時のフック(apply)はあるものの、ノードの更新開始・完了時のフックはありませんでした(applyフックはhostごとに設定できますが実行タイミングはノード個別ではありません)。
ノード更新開始時にフックする方法としてk0sctlが呼び出すk0sバイナリのパスを詐称する、のようなものも考えましたが、k0sctlのバージョンアップ時に不意に壊れるリスクがあるため見送りました。
なので、そのようなフックを使いたければk0sctlをフォークして使うか、PRを送ってマージしてもらう必要があります。
フォークするとk0sctl全体を自前でメンテナンスすることになり、管理が難しくなるため後者を選びました。 github.com
なぜDaemonSetはdrainで削除されないのか
cordonされたノードに付与されるtaintsに対応するtolerationsを持っているからです。
cordonはノードに次のtaintを付与します。
effect: NoSchedule key: node.kubernetes.io/unschedulable
drainはこのtaintを付与した上で、ノード上からPodを削除します。なので、drainされたノードにはこのtaintに対応するtolerationを持たないPodは新しくスケジュールされません。
DaemonSetのPodは次のtolerationsを持ちます。
tolerations: - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists - effect: NoSchedule key: node.kubernetes.io/disk-pressure operator: Exists - effect: NoSchedule key: node.kubernetes.io/memory-pressure operator: Exists - effect: NoSchedule key: node.kubernetes.io/pid-pressure operator: Exists - effect: NoSchedule key: node.kubernetes.io/unschedulable operator: Exists
このtoleration
- effect: NoSchedule key: node.kubernetes.io/unschedulable operator: Exists
を持っているのでcordonされたノードにもDaemonSetのPodはスケジュールされます。
そもそもdrain対象のノードにDaemonSetが含まれる場合には --ignore-daemonsets オプションを付与する必要がありますが、これは付与しないとDaemonSetのPodは消されても復活するので、処理が終わらないからです。
DaemonSetが未対応のtaintを付与する
DaemonSetはあくまでtaints/tolerationsの仕組みによってcordonを無視していました。なので、対応していないtaintがノードにあればDaemonSetであろうとも無視できません。例えば
key: "pixiv.net/not-ready" operator: "Exists" effect: "NoExecute"
のようなtaintを付与すると、そのノードから対応するtolerationを持たないPodは削除され、新しくスケジュールされなくなります。effectに NoSchedule ではなく NoExecute を指定することで即座にPodの削除をすることができます。
Fluentd以外のDaemonSetが巻き添えになってしまいますが、対策は簡単です。対応するtaintをDaemonSetのtolerationで許容すればいいです。 kube-proxy などの主要なDaemonSetは operator: Exists というすべてのtaintsに対応するtolerationをもともと持っていたりします。
k0sctlへPRを送る
issueには新しいhookを追加したいと書きましたが、しかるべきタイミングでのtaint付与・剥奪で十分なことがわかりました。なのでそのようなオプションをk0sctlへ追加するPRを送りました。 github.com
無事v0.24.0でリリースされました。 github.com
私が関わったのは evictTaint という機能です。
これはノードのアップグレードなどが実行されるとき、drainの前にそのノードに指定したtaintを付与します。そのノードがアップグレードされ、uncordonされるとそのtaintを剥奪します。
k0sctl.yamlにはこのように設定して活用しています。
apiVersion: k0sctl.k0sproject.io/v1beta1 kind: Cluster metadata: name: k0scluster spec: options: evictTaint: enabled: true taint: pixiv.net/not-ready=true effect: NoExecute