

おはようございます、ImageFlux開発責任者のharukasanです。3日前の4月14日、ピクシブではPawooが急にリリースされることになりまして、ここ数日はずっとPawooサーバにログインしていました。このPawooサーバ、既にピクシブの監視体制に入っており、アラート受信後インフラエンジニアが障害対応できる仕組みを整えています。案の定、リリース直後の15、16日は週末にもかかわらずアラートを受け取ることになり、サーバにはりつくことになったわけです。どんなシステムであろうとアラートを受け取ったら対応する、それが我らインフラエンジニアです。
pawoo.netの構成
さて、それではまずPawooの構成を見ていきましょう。digすればわかりますがpawoo.netはAWS上に構成されています。数百台以上の物理サーバを常時運用しているピクシブであっても、さすがにこんなにはやく物理サーバは用意できません。このあたりはクラウドサービスが非常に強いところです。4月に入社したばかりのインフラエンジニアnojioと、新卒2年目のkonoizがシュッと構成を用意してくれました。

AWSを最大限に利用することで、作業開始から5時間くらいでインフラが整い、その日のうちにサービスリリースすることができました。
Dockerからはがす
MastodonはDockerコンテナで簡単に起動できますが、複数インスタンスにデプロイするため、Dockerコンテナからはがして運用しています。コンテナに入っているとボリュームとかcgroupとかDocker固有のいろんな問題を考えないといけないので面倒です。「まちがってボリューム消しちゃった!」みたいなことにもなりかねません。この方法はMastodonのProduction Guideにも書いてある方法です。
ということでDockerからはがして各サービスはsystemdで管理することにしました。たとえば、Webアプリケーションのサービスファイルはこんな感じになります。
RDB、Redis、ロードバランサーはすべてAWSのマネージドサービスを使って構成しています。これにより、マルチAZで冗長設計がなされたデータストアをすぐに用意することができました。ALBはWebSocketにも対応しているので、ストリーミングの分散も簡単です。アップロードファイルの置き場もS3を使っています。
AWSのマネージドサービスを活用することで、最速でリリースされたPawooですが、すぐに問題が起こり始めました。
nginxのチューニング
リリース開始当初、nginxはディストリビューションのデフォルト設定のまま動かされていましたが、エラーを返すようになったのですぐ手をいれることにしました。とはいえ重要なのは worker_rlimit_nofile と
worker_connections を増やした程度です。
その後nginxはそれほど頑張って設定しなくても、うまいこと動いてくれました。このあたりは拙著ですが『nginx実践入門』に書いてあります。
コネクションプールを適切な値にあわせる
Mastodonで使われているPostgreSQLはコネクションごとにプロセスをforkする性質をもっており、1コネクションごとに毎回プロセスが起動します。そのため、コネクションを張り直すのは非常にコストが高い処理です。これがMySQLとの最大の違いですね。
RailsとSidekiq、Streaming APIに使うnode.jsにはコネクションプールの設定があります。これを良い塩梅の値に設定してあげましょう。インスタンス数にも注意です。負荷が高いからってアプリケーションのインスタンスを急に増やすとDBが詰まって大変なことになります(なりました)。PawooではAWSのCloud Watchを使ってRDSへのコネクション数を監視するようにしています。
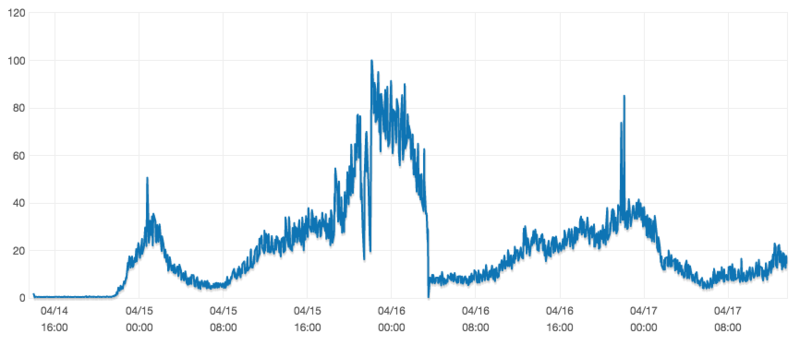
コネクション数が増え続け、詰まって大変なことになったRDSですが、インスタンスのスケールアップを行い、安定稼働に持ち込むことができました。CPUのグラフを見てもメンテナンス後にガクッと下がっているのがわかります。
Sidekiqのプロセス数を増やす
MastodonはメッセージパッシングをSidekiqによって行っています。本来ジョブキューとして設計されているSidekiqですが、トゥート!される度にかなりの数のタスクがenqueueされることになります。リリース当初からSidekiqの処理遅延が大きな問題になっていたので、これをいかにさばくかが、大規模Mastodon運用の鍵になるといえそうです。
Mastodonには標準で4つのキューがあります(Pawooでは改造して5つのキューにしてあります:issue)
- default: トゥートの反映など全般
- mail: メールを送信する
- push: ほかのMastodonインスタンスに更新を送信する
- pull: ほかのMastodonインスタンスから更新を取得する
このうちpush、pullのキューは他のMastodonインスタンスのAPIをリクエストする必要があるため、ほかのMastodonインスタンスが応答できない状態に陥っているとかなりのキューが詰まれてしまい、defaultキューの処理も遅延させてしまいます。これを防ぐため、キューごとにSidekiqプロセスをわけて起動します。
Sidekiqは起動オプションでどのキューを処理するか指定することができるので、これを利用して1台のサーバインスタンスに複数のSidekiqプロセスを立てています。サービスファイルは次のような感じです。
Mastodonで最も混雑するキューはdefaultキューです。たくさんフォローされているユーザがトゥート!すると大量のタスクが一気に積まれます。このタスクを高速でさばかないとキューが詰まる状態になり、タイムラインの遅延を発生させる原因になります。Pawooでは現在defaultキューを720スレッドでさばいていますが、ここをいかに高速化するかが課題になりそうです。
インスタンスタイプを調整する
サービスリリース当初は、どの程度の負荷になるかわからなかったため、適当なインスタンスタイプを選択してスタートしましたが、負荷に応じて何度も調整を行っています。最初はt系のインスタンスを使っていましたが、CPUクレジットを使い切るタイミングで一時的に負荷が上昇するようになってしまったため、c4が中心の構成にしました。将来的にはスポットインスタンスを使ってコスト圧縮を図っていきたいと考えています。
マストドンにコントリビュートする
さて、ここまでインフラ的な側面からMastodonの改善を試みてきましたが、実際サーバを増やすよりもコードを改善した方が効果が高いところがたくさんあります。ピクシブでは複数のエンジニアがMastodonに本体にPRを作成し、改善作業を行っています。
これまでに送ったPull Requestの一例:
- abcang: fix regex filter #1845
- alpaca-tc: ActiveRecord::NotFound -> ActiveRecord::RecordNotFound #1864
- walf443: reduce unneed query when post without attachements. #1907
- ikasoumen: Enlarge font size to avoid autozooming of iPhone #1911
- alpaca-tc: Fixed NoMethodError in UnfollowService #1918
- alpaca-tc: Check @recipient.user at the first #1939
- geta6: Improve streaming API server performance with cluster #1970
今年4月に入社したばかりの新卒エンジニアもPRを送っています。その全ての改善をこの記事で触れることはできませんが、ピクシブで行った改善は今後紹介していきたいと思います。
まとめ
Pawooはまだ運用始めたばかりでこれから大きくなるサービスです。コードもすごい勢いで改善されており、インフラ構成もそれに合わせて変えていく必要があるでしょう。
ピクシブではpawoo.netを立てただけでなく、引き続きMastodonの発展のためにあらゆる改善を行っていきます。そんなピクシブでは一緒にPawooを盛り上げてくれるエンジニアの募集をはじめましたので、ぜひご覧ください!

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.



