

はじめに
初めまして。プラットフォーム開発部にてデータ基盤を整備しているkashiraと申します。
ピクシブでは中央集権的なデータ組織ではなく、非中央集権的なデータ組織(データの民主化)を目指して活動してきました。
その結果データメッシュに近い形で運用出来ていると感じているので、これについて話したいと思います。
ピクシブで非中央集権データ組織を採用した背景
ピクシブでは社員数に対してプロダクト数が多い事情があります。(2023年3月1日時点で正社員294人、15プロダクト)
正しいデータ分析をすることにおいて深いドメインの理解は必須であり中央のデータチームで全てのデータを分析することは現実的に厳しい事情がありました。
また各チームメンバーが自分のプロダクトにオーナーシップを持って取り組み、ユーザーのためにやれることはやる文化があります。
こういった事情から以下の理想を求めてデータの民主化を進めて行きました。
- 社員みんながデータを活用できるようになる
- 社員みんながデータを活用できるようになる結果、深いドメイン知識とデータをセットで活用し、素早くプロダクトを改良していけるようになる
このデータ民主化を進めていった結果として、分析はプロダクトチーム、データ基盤は中央のチームで管理する体制に落ち着きました。
データの民主化に向けた取り組みについては以下のinsideもご覧ください inside.pixiv.blog inside.pixiv.blog
データメッシュについて
データメッシュ(Data Mesh)は2019年にZhamak Dehghani さんが書いた Data Mesh Principles and Logical Architecture にて生まれた組織概念です。
データメッシュは原則として、以下の4つを定義しています
- Domain Ownership
- ドメイン(プロダクト)チームがデータに責任を持つ
- Data as a product
- データは会社の意思決定を判断するための重要な要素なのでプロダクトと同じように扱う
- Self-serve data platform
- ドメインチームがデータパイプラインを管理する際に、共通のテンプレート・CI/CD・環境を用意することでドメインチームが運用するコストを下げる
- Federated computational governance
- データがサイロ化しないようにギルドのような連合組織にて取り決めを行う
この原則に従うことでデータがサイロ化しないようにしつつ、データ利活用を素早く行うことが期待されます。
データメッシュの原則をピクシブでの取り組みに当てはめてみる
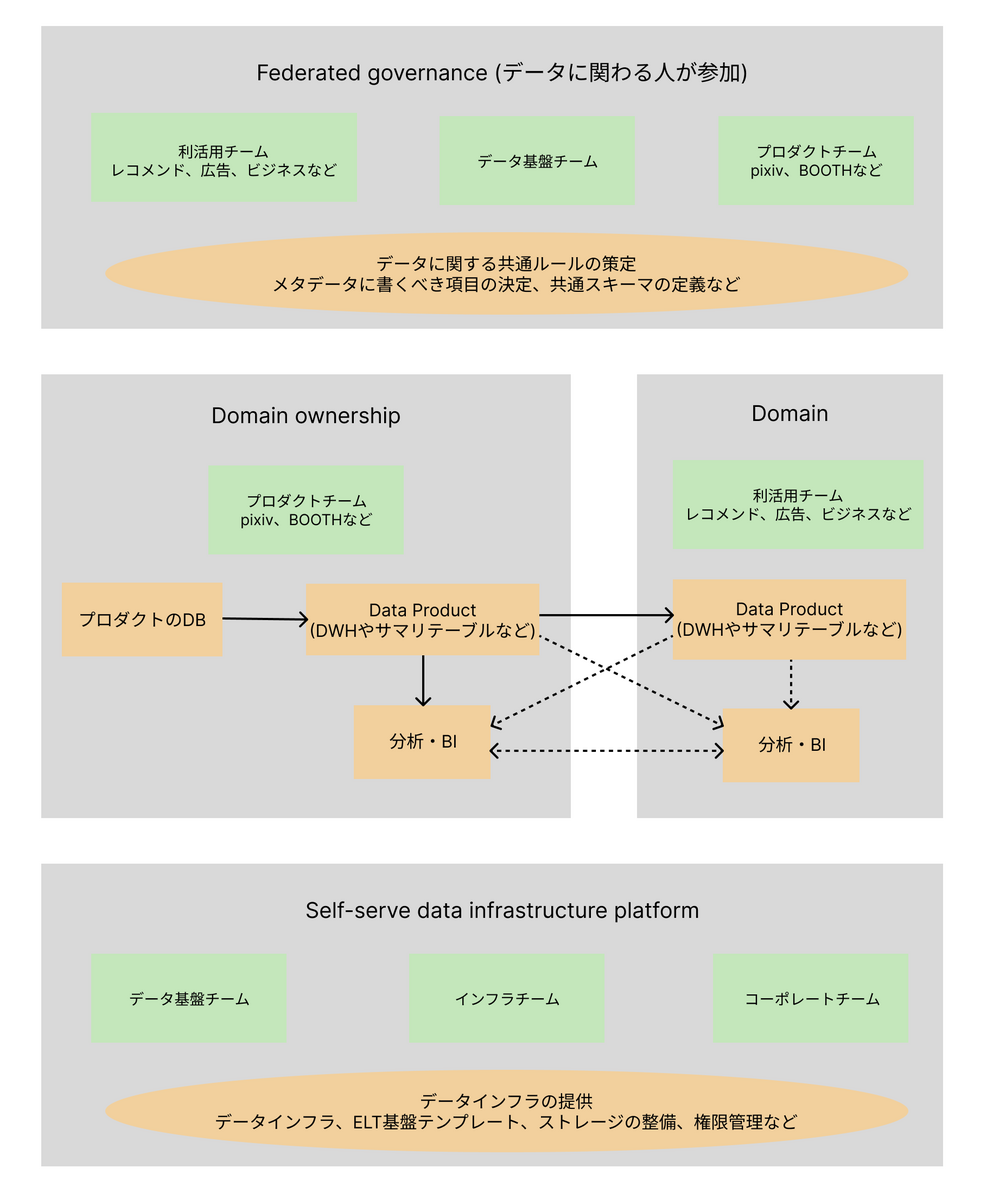
Domain Ownership
ピクシブではデータへの責任はプロダクトチームが持っています。
プロダクトチームはデータ基盤チームが作った全社基盤のELTのテンプレートを使って データパイプラインを構築・アラート対応をしています。
基本的にプロダクトチームに専任のデータエンジニアやアナリティクスエンジニアはいません。メイン業務がフロントやバックエンドなどのエンジニアがデータパイプラインを作っています。
テンプレート・ドキュメントを充実させることで、データ基盤チームの助けなしでもデータエンジニアリングを詳しくないエンジニアがデータパイプラインの作成・管理が出来ています。
部署によってどこまでやるかは変わってきますが、どのプロダクトも
- AirflowのDAGでMySQLのデータをBigQueryに同期(データレプリケーション)する実装
- LookerでのLookMLの作成
まではデータ基盤チームの助けなしで実装しています。
データの利活用が盛んなプロダクトは
- MARTテーブルの作成
- 重要テーブルに対しての独自のモニタリング
- テーブルに対しての独自のテスト
などを実装している部署もあります。ここら辺は必要に応じて実装しています。
また対象のデータについて分からないことがある場合にデータ基盤チームに分析を聞くのではなく、対象データに詳しいプロダクトチームに聞いて分析をする文化が根付いています。
ただしデータに詳しく無い人からの質問はデータ基盤チームに来ることも多く課題に感じています。
Data as a product
弊社では課題だらけの分野になります。
良くも悪くも社内用のデータとしてSLAを厳密に守る必要がなかったり、データの品質に関する文化・それを担保する仕組みが無いのが原因です。
現状で以下のようなものを全社的に広めていくことを考えていますが、まずはそれを実装するための仕組み・ルールの整備が残っています。
具体的には以下のようなことを考えています。
- データテストの充実
- データ品質のモニタリング
- メタデータの充実
- SLA
Self-serve data platform
自分が所属するデータ基盤チームがメインで仕事している部分になります。
具体的には以下のような仕事をしています。
- BigQueryの整備
- ストレージ・スロット・権限周り・監視
- Lookerの整備
- 監視・CI/CDの整備
- 全社共通のELT基盤(Airflow + Embulk)の整備
- テンプレートの実装・利用ドキュメントの整備・CI/CDの整備・バージョン管理
- ログ基盤(fluentd)の整備
- メール基盤(SendGrid + Colab)
ただ、ピクシブでは全社共通のELT基盤は1つのモノレポ的な管理をしています。
データメッシュではマイクロサービス的な考え方を取り入れているので、ここについてはピクシブ固有の運用の仕方をしています。
モノレポ的な管理をしているため、コードの横展開が簡単などのメリットは沢山受けていますが、権限周りやスケール部分で課題を感じています。
またGCP全体の管理はインフラが、社員に対する権限管理はコーポレートが担っているため、この2つのチームとは密接に動くことが多いです。
Federated computational governance
ピクシブではデータエンジニアリング互助会と呼ばれる社内コミュニティとデータ基盤チームが協力しあって各種ルールの策定を行なっています。
互助会ではデータ基盤の更新を共有したり、BigQueryやLookerの新機能の共有、各種プロダクトで困っているところの解決の場として利用されています。
- 全社で利用されるピクシブのユーザー情報サマリのスキーマレビュー
- bq-batchのフォルダ分けの命名規則の決定
- データセットの命名規則の決定
- など
互助会についての取り組みを知りたい場合には以下のinsideもご覧ください。
運用してみて難しいと感じた所
他にも問題となる点はありますが、自分が業務をしている上で特に課題と感じた点を書きます。
データ利活用の促進
データの利活用の度合いがチームによって大きく違います。データに強い・データに関心の高い人材のいる部署は自律的にデータの利活用が進んでいます。
一方でデータに関心がない・データに強くない部ではデータの利活用が十分に進んでいないケースが散見されます。(特にエンジニアがいない非プロダクト系の部署)
こういった全社的なデータ利活用を促進していく仕組みづくりを構築していくのが難しいと感じています。
ドメインチームのデータスキルが高いことが求められる
データ関連の業務を兼任して貰うに当たって、ドメインチームに、プロダクト技術とデータエンジニアリングの両方に精通した人材が存在する必要があります。
この両方が揃えた人材は市場にあまりいないので、このキーマンをどう育てるのか?というのは考えた方が良いと考えています。
ピクシブでは各チームに1人、分析に強い人間を作ることを目標にデータ駆動推進室という組織を作り、データに関心のある人材がデータ関連の業務を密に担当していた経緯があります。
この取り組みのおかげでFederated computational governanceがうまく動いていると感じています。
現在はデータ駆動推進室のメンバーが抜けていないため、健全な状態で運営されていますが、プロダクトとデータエンジニアリングにも精通している人物が増えていないため人への依存度が高いのが問題には感じています。
中央のデータ基盤チームがボトルネックになる
近年はDWHも成熟し、周辺のツールが急激に成長しています。
これらのツールを導入して業務改善をしたくても全社基盤を利用していると、データ基盤チームがのリソースがボトルネックになり容易に導入を進められないケースが発生しています。
こういったケースに関しては、全社基盤を待たずに新規に利用しているプロダクトもあります。
このようにデータ基盤が分散した際にどうするかについては考える必要があると考えています。
データ基盤の権限設計が複雑になる
これはデータメッシュというより、ピクシブがモノレポ的にデータパイプラインを管理しているのが原因ですが、データ基盤の権限設計が複雑になりがちです。
プロジェクトやリソースが分離している場合にはサービスアカウントに必要な権限を付ければ良いのですが、様々なプロダクトが同居している場合はコードを書けば好きにデータを取得し放題な状態になります。
ここはチーム内で強く課題に感じているため対策を考えていますが、まだ対策できていないです。
まとめ
ピクシブではデータメッシュに近い組織構造でデータの利活用をしています。
改善すべき課題はまだまだありますが、データが欲しいエンジニアなら誰でもデータを繋ぎこめる・分析出来る環境があるため、それぞれのプロダクトチームでスピード感を持ってデータ利活用出来ています。
最後には弊社ではデータマネジメントエンジニア・データアナリストを大募集しています。


