

イントロ
こんにちは、pixivおすすめ改善チームの三好 (@mytk) です。今日は、pixivの作品ページのレコメンドに多様性を持たせるべく、BigQueryのUDFを利用し1クエリでレコメンドの多様化を実現した事例を紹介します。
Topic Diversification Algorithmとは
Zieglerら (Ziegler et al, 2005) が提案したTopic Diversification Algorithm (以下TDA) は、関連度順に並んだ推薦リストに対して、多様性を与えるような並び替えを行う手法です。
関連度順に並んだ推薦リスト とし、TDAによって並び替えられた推薦リストを
とすると、
から
への並び替え手順は、おおまかには以下のようになります。
- 空のリスト
を用意する
- もとのリスト
の中で最も関連度の高い推薦アイテムを
- その推薦アイテムの (A) の順位 (降順) と (B) の順位 (昇順) に基づき、スコアを計算を行う
手順4では、それぞれのアイテムに対して (A) の順位 (降順) と (B) の順位 (昇順) の重み付け平均を計算し、その値を最小とするような推薦アイテムを求めます。 (A) の順位が高いことは関連度が高いことと、また (B) の順位が高いことは既に に含まれている推薦アイテムと似ていないことと対応します。
詳しい計算方法については、解説記事や論文などをご覧いただければと思います。
BigQueryを用いた実装
pixivで用いられるレコメンドの多くは、一度BigQuery上のテーブルを経由してからアプリケーションのDBに送られます。したがって、TDAがSQLで実装できることは、あらゆるアルゴリズムに対してTDAが適用できることを意味していました。
TDAには繰り返し処理などがあるため、通常のクエリでTDAを実装することは困難です。しかしBigQueryではユーザー定義関数 (User-Defined Functions) という機能がサポートされており、これによってJavaScript関数を作成し、クエリに適用することができます。TDAの適用は、「関連度順に並んだアイテムの配列」と「推薦先のアイテムどうしの類似度」をもとに、「推薦アイテムどうしの関連度を考慮したアイテムの配列」を返すUDFの呼び出しとみなせます。
以下では、これを実現するサンプルコードを抜粋して紹介します。なんとなく実現可能そうな雰囲気を掴んでいただければ幸いです。
↓こちらは、サンプルコードで利用しているテーブル (20行) です。
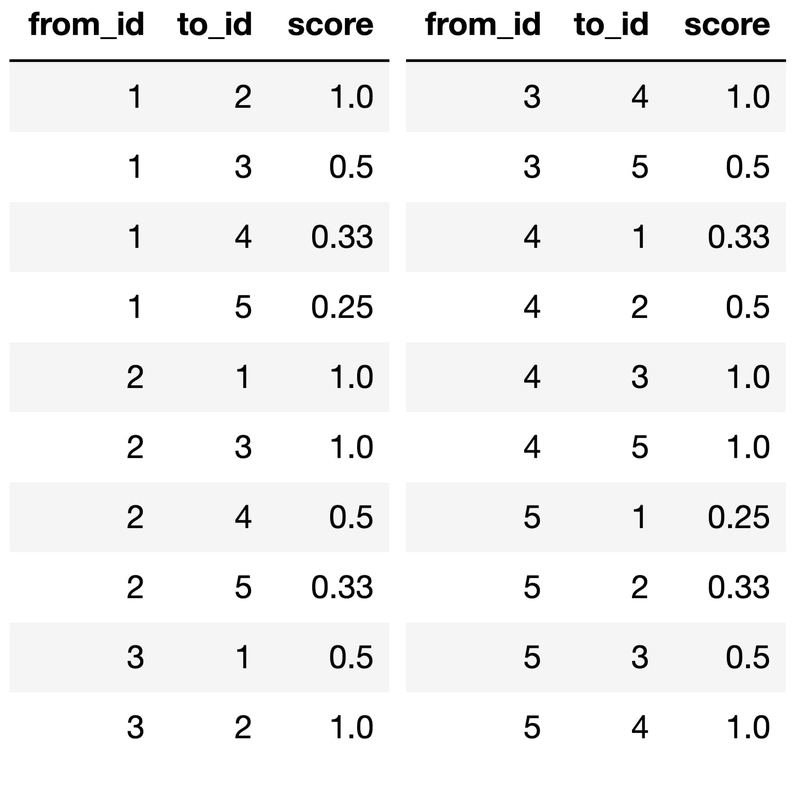
最後のJOINは多少複雑ですが、以下のように、最初のINNER JOINで推薦アイテムどうしの組み合わせを求め、2回めのINNER JOINでそのIDの組み合わせの類似度を取得しています。
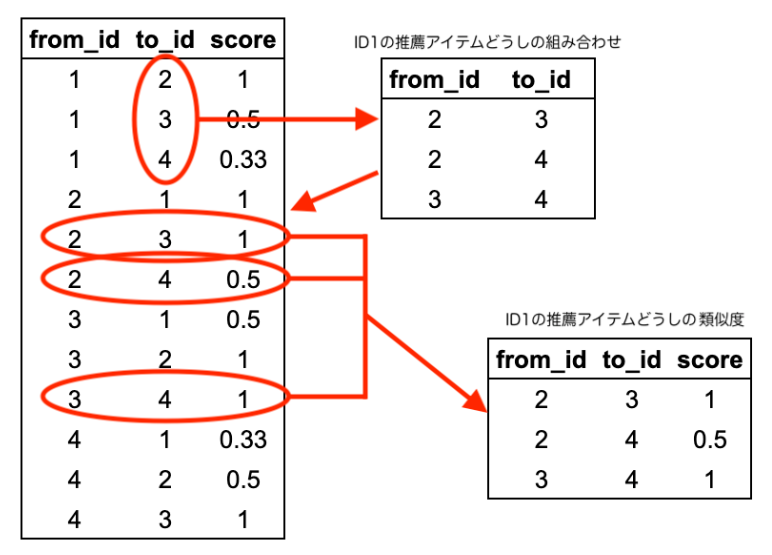 ちなみに私が実装した限りでは、このクエリのボトルネックはUDFではなくこのJOINでした。また実際には、2度目のJOINで結合する類似度テーブルは
ちなみに私が実装した限りでは、このクエリのボトルネックはUDFではなくこのJOINでした。また実際には、2度目のJOINで結合する類似度テーブルは data 自身ではなくTDA用に別途用意したものになります (もとのアルゴリズムによらず、共通の類似度を用いてTDAを適用するため)。
施策効果
TDAによる並び替えを、pixivの作品詳細ページで使われているアルゴリズムの1つに適用し、ABテストしてみたところ、作品詳細ページでクリックされたユニークイラスト数が10%近く増加したほか、クリック数やブックマーク数も大幅に (レコメンド件数の少ないモバイル版で10%程度、件数の多いPC版で5%程度) 増加しました。
また、アルゴリズム単体でみると、クリックされたユニークイラスト数が80%程度増加したうえ、そのクリック数もモバイル版で30%以上、PC版で50%以上増加していました。
一般に、レコメンデーションにおける精度と多様性にはトレードオフ関係があるとされているため、今回の施策によって精度が低下することで、クリック・ブックマーク数に悪影響が及ぶ可能性もあるかと思っていましたが、実際には、並び替えによる多様化の恩恵がそれを上回ったようでした。
最後に
BigQueryのUDFを駆使すれば、TDAはたった1つのクエリで実装することができます。 「レコメンドをより多様化したいが方法がわからない」「TDAを試してみたいけど手段がわからない...」と思っていた方のお役に立てたなら幸いです。



