

pixivの小説を改善している Webエンジニアの pawa です。
今年の3月、「言語処理学会 第25回年次大会(以下NLP2019)」に参加してきました。(言語処理学会の雰囲気は他社のブログで既に書かれているために省略します。)
学会参加後、pixiv の小説に応用できそうなテーマで、社内の勉強会にて3回ほどプレゼン発表して知識共有してきました。
社内勉強会での発表タイトルは以下の通りでした。
・テキストの読みやすさ
・読点の自動挿入
・文学作品における話者同定
今回は、この中でも創作作品を楽しむ上での応用範囲が広い「話者同定」を紹介します。「話者同定」は小説サービスで応用するにはまだまだ精度が足りない課題です。この記事がきっかけでこの問題に取り組んでくださる方が現れるならこの上ない喜びです。
目次
話者同定とは何か
辞書で「同定」を調べると、「① ある物をある一定の物として認めること。あるものとあるものの同一性を認めること。」(Macの「スーパー大辞林」より引用)と書いてあります。
文学作品における話者同定 (Speaker Identification) は、物語文中の発話の話し手を同定する(あるセリフが誰のセリフかを特定する)タスクとなります。
話者同定ができるとどういう価値を届けられるようになるか
pixivの小説で話者同定ができるとユーザーの皆様にどのような価値を届けられるようになるかを考えてみました。
- ① 作品を機械で読み上げるときに同定された話者によって声色を変える
- ② 同定された発話を分析することで作品の登場人物の特徴を自動抽出する
- ③ 話し手だけでなく聞き手も同定することで登場人物同士の関係を推定する
①:同定された話し手の特徴(性別・年齢・性格等)を地の文から取得・推定できれば、それに概ね合致する声色を生成可能になるのは遠くない未来であると考えます。ただ、NPO日本朗読文化協会主催「朗読の日」の公演を聴いた限りでは、細かい文脈にも合う「この世を生きてきた人間の朗読」に匹敵するにはそこからさらに時間がかかると考えます。
②:登場人物と結び付けられた発話から、その登場人物の言葉遣い・ある事象が生じたときにどういう反応を示すか(思考の癖)などの情報も取得できそうです。それにより、登場人物のタイプによる作品検索を提供したり、あるいは、特定のタイプの登場人物が出る作品が好きな読者に同様の登場人物が出る他の作品をおすすめすることもできそうです。
③:登場人物の相関図も自動で描けるようになりそうです。ただ、それがどれだけ「作品を読む」行為に寄与し得るかはまだ不明です。他の応用としては、登場人物同士が特定の関係である(または特定の関係に遷移する)作品を検索できる可能性も秘めています。
②と③に関しては、pixiv小説の「タグ付け機能」により、著者あるいはユーザーが付けたタグで一部分では既に価値が届けられている面もあります。しかし、すべての作品が著者やユーザーから適切かつ十分な量をタグ付けされることを期待するのは難しいのが現実です。そのため、②と③に関しても話者同定からアプローチする意義は十分あると言えるでしょう。
以下、話者同定にはどういう難しさがあって、それに対して現状の研究ではどういうアプローチで挑んでいるかを知れることを目指して綴っていきます。
話者同定の大まかな3ステップ
私が文献を読んだ限りでは、話者同定タスクは大まかに以下の3ステップで構成されることが多いと分かりました。
1.物語文章中の発話を特定
2.発話と「参照表現としての話者」の紐付け
3.「参照表現としての話者」と「実体としての話者」の紐付け
各ステップの意味は後ほど説明するため、現状ではぼんやりとした理解で問題ありません。
発話の特定の難しさ
話者を同定するにはいろいろなアプローチが考えられますが、一般的なアプローチにおける初手は「発話の特定」です。
人間は物語文章を読んで問題なく発話を認識できますが、日本語の物語文章においてはコンピュータにはどの部分が発話文かを認識することすら困難なのが現状です。カギ括弧に囲まれていればほぼ発話であるかのように思われますが、学生の頃に私が調査した結果では、発話以外のカギ括弧の使われ方も散見されました。発話以外でカギ括弧がどのように使われているかを見てみましょう。
カギ括弧を用法で分類してみた 〜発話の特定を目指して〜
適当に頭に思い浮かんだ長すぎない文学作品4作品のカギ括弧(「」or『』)の使われ方を調査してみました。4作品だけでも「思考」「強調」「オノマトペ」「固有名詞」「伝聞」「引用」という「発話」以外の使われ方が見つかりました。(この分類は自身で適当に考えて作りました。もっと多くの作品を調べると他にも用法があるかもしれません。)
①思考
例:「なぜ? なぜ?」兄さんを憎く思いました。
②強調
例:それこそ「カナリヤのお食事」みたいに
③オノマトペ
「擬音語・擬声語・擬態語を包括的にいう語。」(Macの「スーパー大辞林」より引用)
例:「ごろごろ」という雷の音が
④固有名詞
例:私は「ピクシブ」のWebエンジニアです。
⑤伝聞
例:「水が濁るとよくないことがある」と云われている湖
⑥引用
例:「渡るな!危険」と書かれた看板
⑦例外
その他にも、「もし『・・・』と言ったら」というような、実際に発話している訳ではない、分類できないものもありました。ごく稀な用法なのでこれは無視しました。
それぞれの用法の頻度を表にまとめると以下のようになりました。
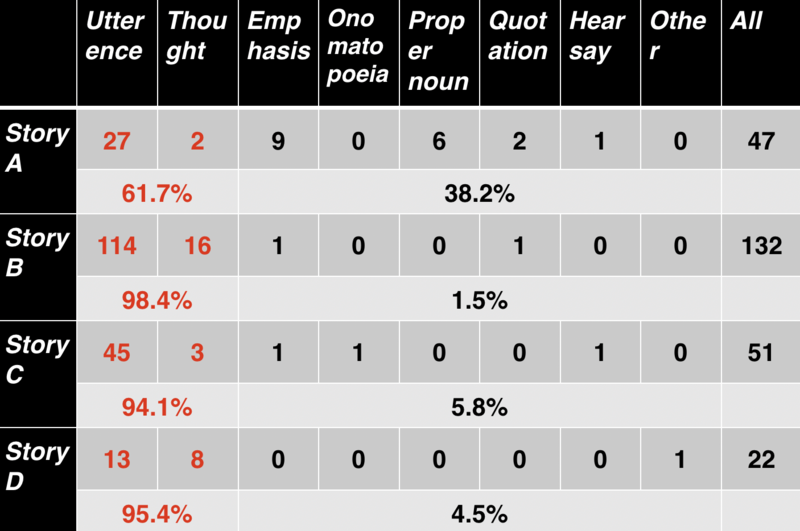
StoryA: 太宰治『女生徒』
StoryB: 海野十三『火葬国風景』
StoryC: 夢野久作『ルルとミミ』
StoryD: 芥川龍之介『トロッコ』
(私が偶然に思いついた作品を著者が重ならないように選びました。)
「思考」を「発話」扱いにすれば、Story B,C,D で見ればカギ括弧ならば発話とみなしても 94.1% 以上で正解となります。 しかし、StoryA が入ってくるとその条件下でも 38.2% で不正解となるので、カギ括弧ならば「発話」(思考も含めて)という想定ではまずいことが分かります。
上記4作品を読んだ限りでは、文中のカギ括弧ではなく文頭のカギ括弧ならば発話(あるいは思考)のカギ括弧である確率が高いと感じました。そのため、文頭のカギ括弧のみを対象とする場合も調べてみました。結果は以下の表の通りとなりました。
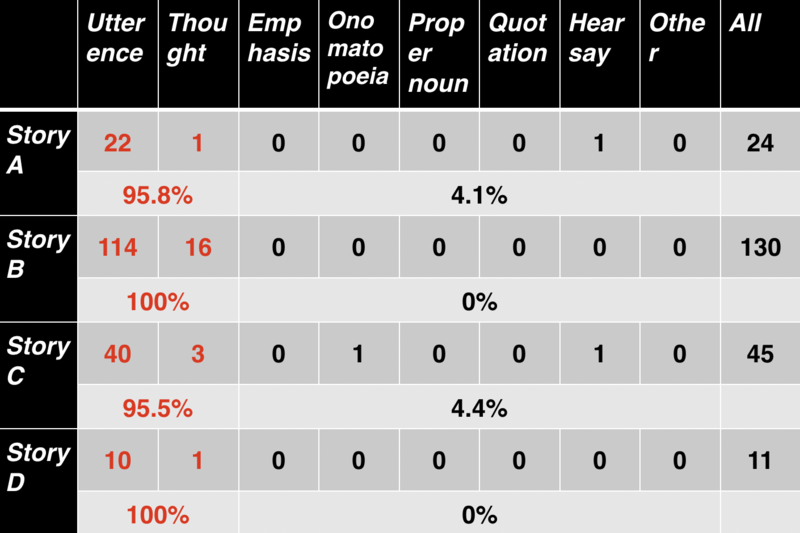
発話(と思考)の割合が非常に高くなりました。しかし、依然として間違いが4%を超える作品も存在します。実際に機械で読み上げる応用を考えると4%でも高いと感じることでしょう。作品によっては不正解率がもっと高い作品もあることが予想されます。大量の作品の文頭のカギ括弧を分類した場合にどういう不正解率(発話・思考じゃない率)になるのかはおそらく誰も調査していないために不明です。全ての発話を網羅するのを諦めて一文が1つのカギ括弧ペアで閉じているのものに限定すればもう少し正解率は上がりそうです。
このように、カギ括弧が発話かを特定するだけでも中々難しく、その後の話者同定では難易度が跳ね上がります。
話者同定タスクでの発話抽出(発話特定)
前述の通り、話者同定の前段階として物語文章から可能な限り正しく発話を抽出(特定)する必要があります。
今回参加したNLP2019で発表された「文学作品における教師なし話者同定」(https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P6-13.pdf) では、英語で書かれた作品を対象としていました。英語の物語文章では単純なパターンマッチングで99%を超える正解率で発話抽出できるようで、この発表では、システムの入力時点で発話が完全に抽出されている状態であるということで話が進んでいました。
日本語の場合は「物語テキストにおけるキャラクタ関係図自動構築」(https://www.anlp.jp/proceedings/annual_meeting/2008/pdf_dir/D2-3.pdf) で話者同定について書かれていますが、こちらでは発話はおそらく手動で抽出されています。日本語の物語文章で発話の抽出を99%を超える正解率で完全に自動化したい場合の良い方法は私の調査範囲内では見つかりませんでした。
話者候補の抽出
何らかの手法で発話を抽出したあとは、抽出した発話と話者を結びつけるための話者候補抽出を行います。
NLP2019で発表された「文学作品における教師なし話者同定」(https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P6-13.pdf) では、Stanford CoreNLP という文章解析用のソフトウェアで作品の文章を解析して「人名」を登場人物として抽出しています。しかし、実際の物語作品では「人」以外の一般名詞ですら発話しうることから不完全なやり方であることが分かります。
「人名」(固有名詞)以外の話者も拾いたい場合は、WordNetという概念辞書と品詞のパターン列を使った手法や、発話系の動詞に係っている名詞を抽出する手法などもあります。作品内での登場人物の参照のされ方は当然のように一通りでないので、姓と名で別の登場人物として抽出されることもあります。(異なる表記の同一人物の重複をどう扱うかは分析者によります。)
このように、話者候補をうまい具合に抽出するだけでもとても難しいタスクであることが分かります。
話者(参照表現)と発話の紐付け
参照表現というのは、登場人物の参照の仕方は一通りではない(例えば、代名詞やニックネームなども使われる)ため、話者の「実体」とを区別するための用語です。
話者候補作成後は、発話の近くの登場人物名や代名詞の出現パターン,発話系の動詞に係っている登場人物名・代名詞・有生名詞,呼びかけのパターン,発話のみが連続する場合は交互に紐付ける――などの手がかりを利用して「参照表現(これが実体となる場合もある)としての話者」と発話を紐付けます。
参照表現としての話者と実体としての話者との紐付け
参照表現としての話者と発話を紐付けた後は、それを実際の登場人物(実体としての話者)に紐付けます。(だんだんと自身でも何を言っているのか分からなくなりそうな表現ですが。)これにもいろいろな解き方がありますが、先行研究である「A Two-stage Sieve Approach for Quote Attribution」(https://www.aclweb.org/anthology/E17-1044) とは違って、NLP2019で発表された「文学作品における教師なし話者同定」(https://www.anlp.jp/proceedings/annual_meeting/2019/pdf_dir/P6-13.pdf) では、これをクラスタリングという手法で解いています。長くなりすぎるので、もし興味が湧きましたらPDFで詳細をご覧ください。
大まかにこれらのステップで話者同定ができます。
精度は実用にはまだまだ程遠いという具合です。話者同定の応用範囲は広く、文学作品をより楽しめる可能性を秘めているのでさらなる研究が待たれます。
SEE ALSO
発話文への発話者情報付与の基本設計 -『現代日本語書き言葉均衡コーパス』収録の小説を対象に-
以下の図のように様々な発話例を提示されています。

(「発話文への発話者情報付与の基本設計 -『現代日本語書き言葉均衡コーパス』収録の小説を対象に-」 p.47 図2 を引用)
