

こんにちは、インフラ部の id:sue445 です。
GitLabのGCP移行3部作の最後になります。
前回までの記事はこちらになります。余談ですが前編・中編・後編で合計約4万字になりました。
今回の目次
- 今回の目次
- やったこと5: 移行時の作業の洗い出し
- やったこと6: 直前の作業を実施
- やったこと7: 実際の移行作業
- やったこと8: 移行後の対応
- 移行直後のトラブル対応事件簿
- おまけ:移行後の面白メトリクス
- 所感
- 最後に
やったこと5: 移行時の作業の洗い出し
notionでメンテナンス手順書を作成し、
- 移行日までにやること
- 移行当日にやること
- 移行後にやること
のような粒度でやることを洗い出しました。
やったこと6: 直前の作業を実施
細かい作業は色々あったのですが大きな作業はこの辺です。
GitLabをcloneするサーバに対してssh configを配置
旧GitLabでは gitlab-old.example.private のようなイントラ内で使えるDNSのエンドポイントを使っていたのでイントラ内であれば何もしなくてもGitLabにつながる状態でした。
しかし前エントリで書いたように新GitLabからcloneするにはGitLabをcloneするユーザの ~/.ssh/config をいい感じにする必要があります
データの整合性との兼ね合いで移行日までは新GitLabは開放しない予定だったのですが、ssh configへの設定追加は移行前に行っていても既存環境に問題が無いため移行前に対応しました。
具体的には下記のように100台以上のサーバに対して設定を適用していきました。
- pploy*1のあるデプロイサーバ
- 各APサーバ
- デプロイサーバからrsyncで転送している場合は不要なのだが、capistrano*2のように各APサーバ内からgit cloneしている場合には全台必要
- Ansibleのplaybookで10個以上、サーバ台数でいくと50〜60台くらい
- インフラ用の監視スクリプトがGitLabで管理されており、そのスクリプトがピクシブの全サーバで動いていたのでAnsibleで管理している全サーバに適用(数百台)
- Jenkinsが動いているサーバ
- Jenkins controllerとnodeで計10台くらい
基本的にはAnsibleを流すだけではあったのですが、playbook内でssh config周りの設定は共通化されておらずplaybookごとに管理方法が独立していたので個別対応するのが地味に大変でした。
1つずつ調べなからやったのでここだけで10日くらいかかったと思います。
やったこと7: 実際の移行作業
詳しくはメンテナンス手順書に書いてますがおおまかには下記のような作業を行いました。
時間のかかった作業は所要時間も併記しておきます。
- 旧GitLabでの作業
- 旧GitLabをメンテイン
- nginxを止めつつ、gitユーザでsshできないようにする
- gitリポジトリの最後の差分を
gsutils rsyncでGCSに転送(20分) - gitリポジトリを除いた必要最低限のバックアップを手動で作成してGCSに転送 (9分)
- 旧GitLabをメンテイン
- 新GitLabでの作業
- GCSにあるバックアップをリストア&
gsutils rsyncでGCSからAPサーバに転送(2つ合わせて28分) - 移行後に利用する設定をデプロイ(9分)
- 旧GitLabでのみ利用していたGitLab Runnerをコンソールから削除
- 新GitLabで利用するGKEのGitLab Runnerを登録
- OneLoginのロールの設定変更を行い旧GitLabにログインできていた人を全員ログインできる状態にした
- GCSにあるバックアップをリストア&
- 旧GitLabで使っていたnignxに旧URLから新URLへのリダイレクトを入れた
- 細かい動作確認
ここまで終わった段階でメンテアウトしていったん開放しました。(ここまででだいたい3時間弱)
その後、休日出社してた人達で分担して主要サービスで実際にpployからデプロイできるかを確認してまわりました。
当日中に全サービスデプロイ確認できると良かったのですが、意外に時間がかかって全サービス終わりませんでした。
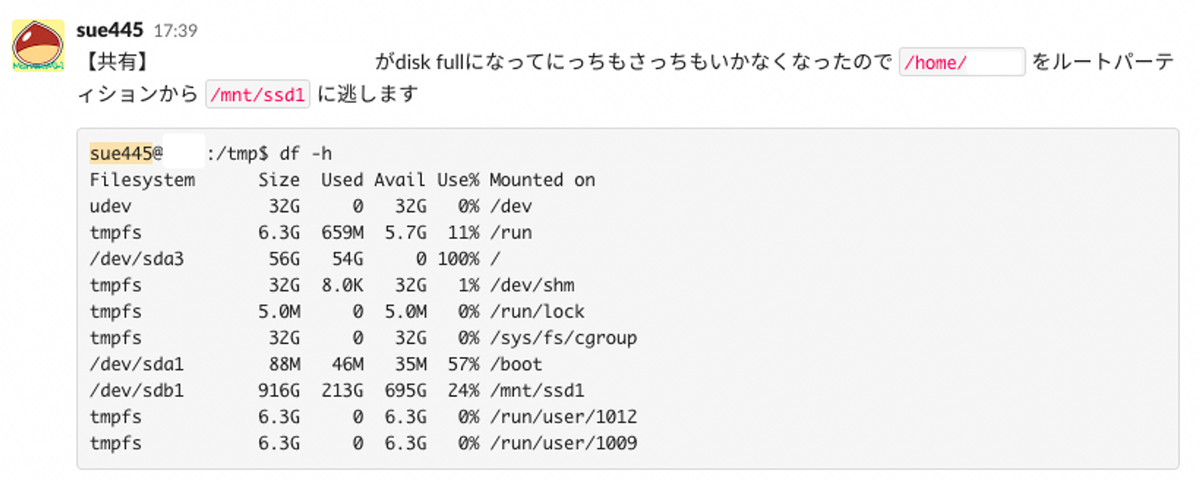
あと、デプロイ確認中にアプリの開発環境がdisk fullになったので泣きながら対応してました。(mvだけで40分くらいかかった…)
やったこと8: 移行後の対応
移行後3日間くらいは常に界王拳3倍状態で仕事していてマジで疲れました...
やったことはだいたいこんな感じです。
主要サービスで実際にGitLabをcloneしてデプロイできるかを確認(残り)
移行日にある程度はデプロイ確認できたものの、それでもpployだけで残り40個以上ありインフラ部だけで全部やるのは無理と判断して作業内容をまとめて各チームにやってもらうことにしました。(各チームで対応するのが難しいものをインフラ部で対応)
社内ドキュメントなどで旧URLになってるものを新URLに変更
旧URLから新URLへのリダイレクトが効いていて緊急性はないため、後日の対応にしていました
移行直後のトラブル対応事件簿
OneLoginのロール付与漏れ
移行後だとOneLoginのロールを利用して
- 正社員は全員GitLabにログイン可
- 正社員以外は明示的にロールを付与しないとGitLabにログインできない
ような仕組みにしていました。
そのため移行前に正社員以外でGitLabにいたユーザ(60人くらい)にロールつけていたのですが、移行後にロール付与が漏れているユーザが発覚してなんやかんやで20人くらい対応していました
移行して3日後に急にデプロイサーバでcloneできなくなった
移行して3日後くらいに急にpployからgit cloneできなくなって困った件です。
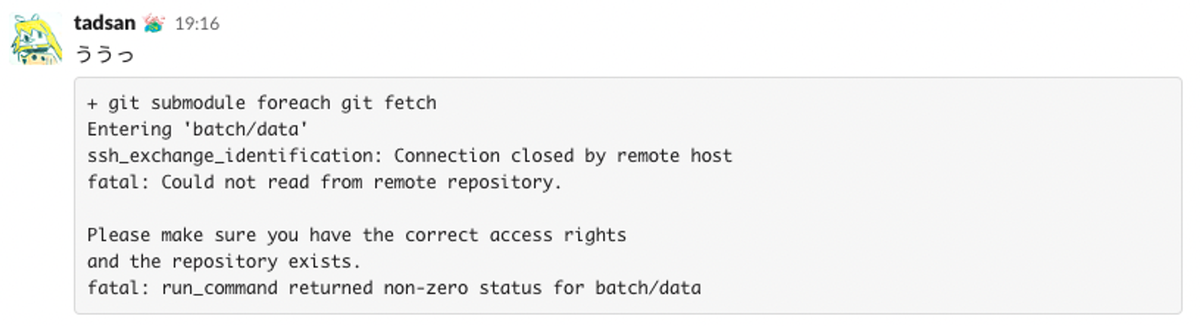
移行直後なら分かるんだけど3日後だったので本当に謎なんすよね…
対応内容1: 踏み台サーバが詰まってそうだったのでスペックを上げた
詰まった時間帯のメトリクスを見ていたら踏み台サーバで急にメモリ使用量が3倍くらいになってトラフィックが虚無になっていました。
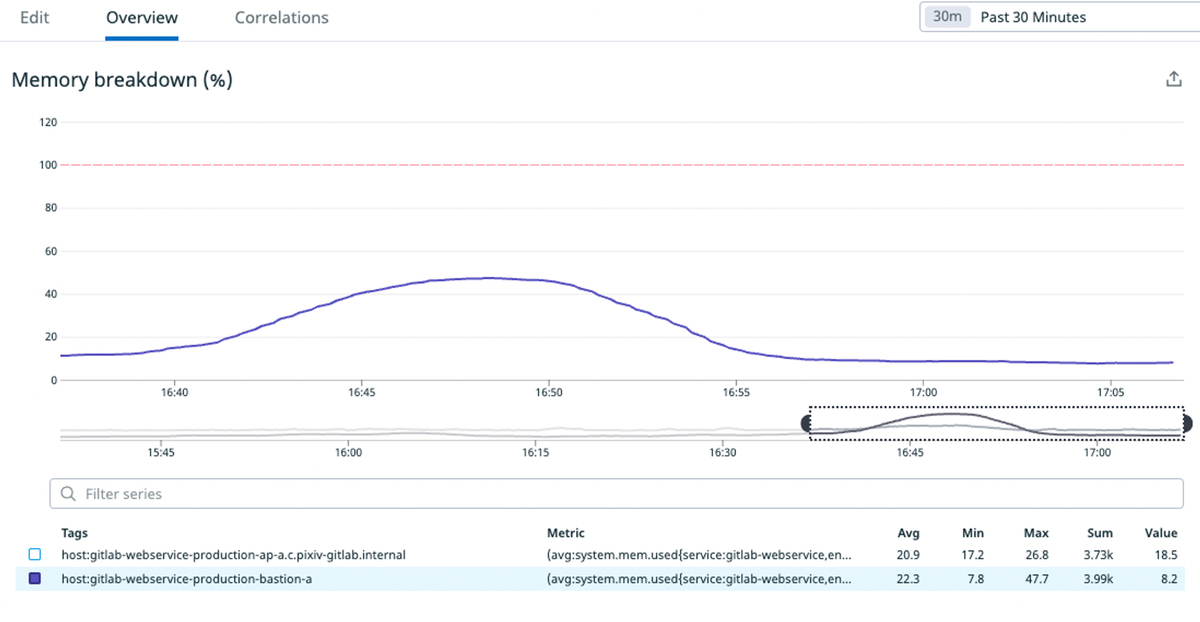
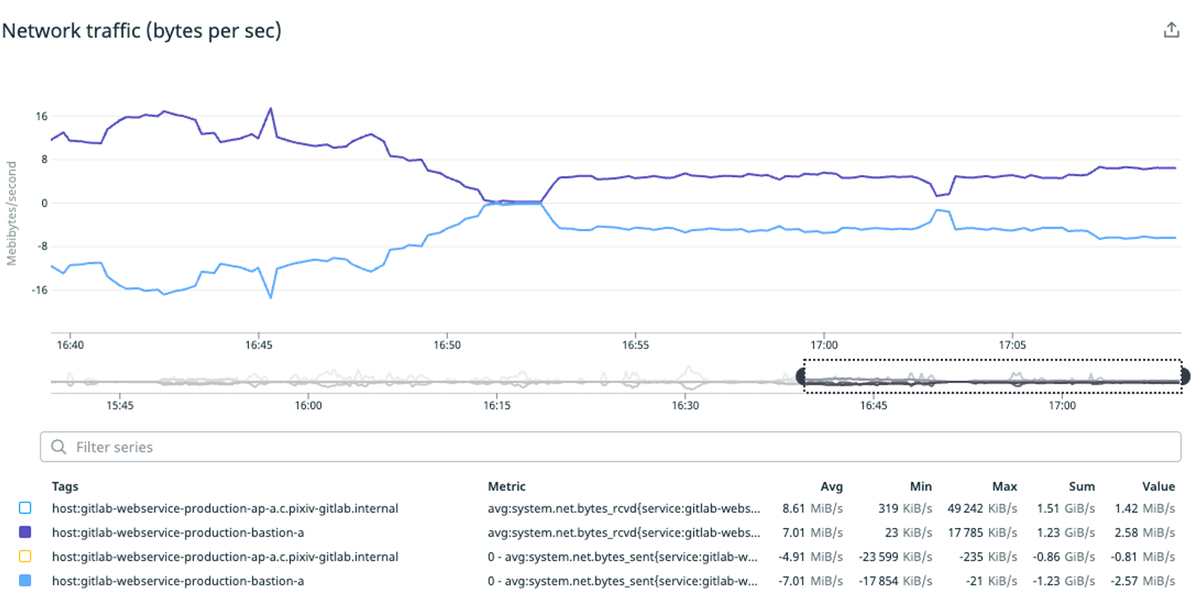
https://cloud.google.com/compute/docs/network-bandwidth#vm-out によるとVMのvCPU数が帯域に直結しているのでvCPU数を2倍にしつつ、瞬間的にメモリの使用量も増えていたので念の為メモリも2倍にしました。
対応内容2: File Descriptorを増やした
File Descriptorがデフォルト値になっていたので念の為踏み台サーバのFile Descriptorを65536に増やしました。(ついでにGitLab本体のあるAPサーバも同様に対応)

対応内容3: デプロイサーバのssh agentのプロセスをkillした
デプロイサーバでssh-agentのプロセスが大量に残っていたのでkillしました。

ここまでやっていったんは解決したのですが、しばらくするとまたちょいちょい再発するようになりました。
対応内容4: sshd_configでMaxStartupsを設定
sshdが怪しいなと思って https://gitlab.com/gitlab-org/omnibus-gitlab との設定差分を見比べていたら /etc/ssh/sshd_config に差分があるのが気になりました。
Debian Busterの初期状態だと /etc/ssh/sshd_config は下記のようになっていました。
MaxStartups 10:30:100
しかしomnibus-gitlabでは下記が設定されていました。*3
MaxStartups 100:30:200
https://man7.org/linux/man-pages/man5/sshd_config.5.html によるとMaxStartupsは
Specifies the maximum number of concurrent unauthenticated connections to the SSH daemon. Additional connections will be dropped until authentication succeeds or the LoginGraceTime expires for a connection. The default is 10:30:100.
のように書かれています。
これは認証されていない段階のsshの最大同時接続数の設定のようです。
試しにMaxStartupsをomnibus-gitlabと同じ値( 100:30:200 )にしたところ、2週間程度経っても問題が再発しなくなったので解決したように見えます。
GitLab CIのpodが消えないことがあった
GitLab CIのKubernetes executerではジョブ実行時にpodを作成し、ジョブ終了時にpodを削除します。
しかし極稀にこのpodが消えてくれず、podが残り続けているせいでGKEのオートスケールnodeの台数が減らない事象が発生していました。
そのため https://gitlab.com/gitlab-org/ci-cd/gitlab-runner-pod-cleanup を導入して、3時間以上起動してるpodは自動的に削除するような仕組みを導入しました。
jpeg画像をアップロードするとエラーになる
事象はすぐに確認できたのですが、移行前後でGitLabのバージョンは変えていないしSentryにもエラーが飛んでいなくてマジで謎でした
ログファイルを調べていたら下記のようなエラーが出ていました。
{"command":["exiftool","-all=","--IPTC:all","--XMP-iptcExt:all","-tagsFromFile","@","-ResolutionUnit","-XResolution","-YResolution","-YCbCrSubSampling","-YCbCrPositioning","-BitsPerSample","-ImageHeight","-ImageWidth","-ImageSize","-Copyright","-CopyrightNotice","-Orientation","-"],"correlation_id":"01GG9YAGCWKW87RFTR86DBZZS6","error":"exit status 2","level":"info","msg":"exiftool command failed","stderr":"Can't locate mro.pm in @INC (you may need to install the mro module) (@INC contains: /opt/gitlab/embedded/bin/lib /etc/perl /usr/local/lib/x86_64-linux-gnu/perl/5.30.0 /usr/local/share/perl/5.30.0 /usr/lib/x86_64-linux-gnu/perl5/5.30 /usr/share/perl5 /usr/lib/x86_64-linux-gnu/perl/5.30 /usr/share/perl/5.30 /usr/local/lib/site_perl /usr/lib/x86_64-linux-gnu/perl-base /opt/gitlab/embedded/lib/exiftool-perl) at /usr/lib/x86_64-linux-gnu/perl-base/overload.pm line 123.\n","time":"2022-10-26T10:45:03Z"}
このエラーログでググると下記のようなissueが見つかりました。(GitLabのDockerイメージのバグ)
GitLab移転時点では15.2.2だったのですが15.3でなおっていたためこの機会に一気に当時の最新版(15.5.2)まで上げることにしました。
Cloud NATの料金が異常に高い
移行後の半月でCloud NATで約21TBの通信量が発生して、それが結構な費用になっていました 🥺
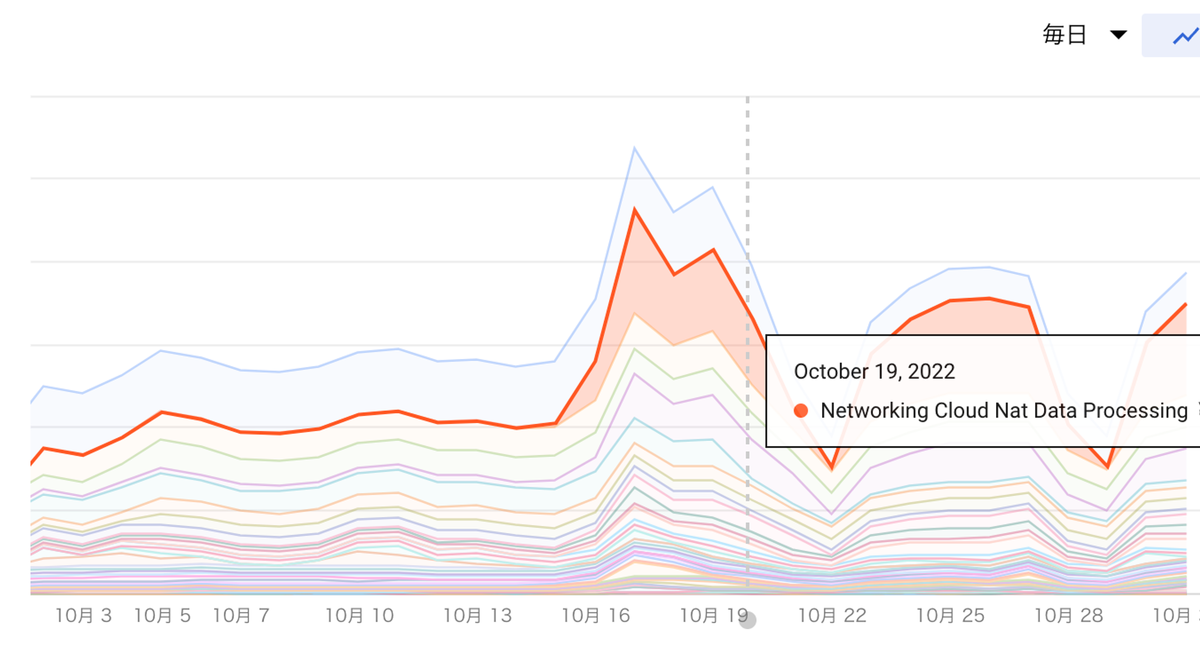
「どう NAT なっとるんだ」ということでまずはCloud NATの転送量をDatadogで見れるようにしました
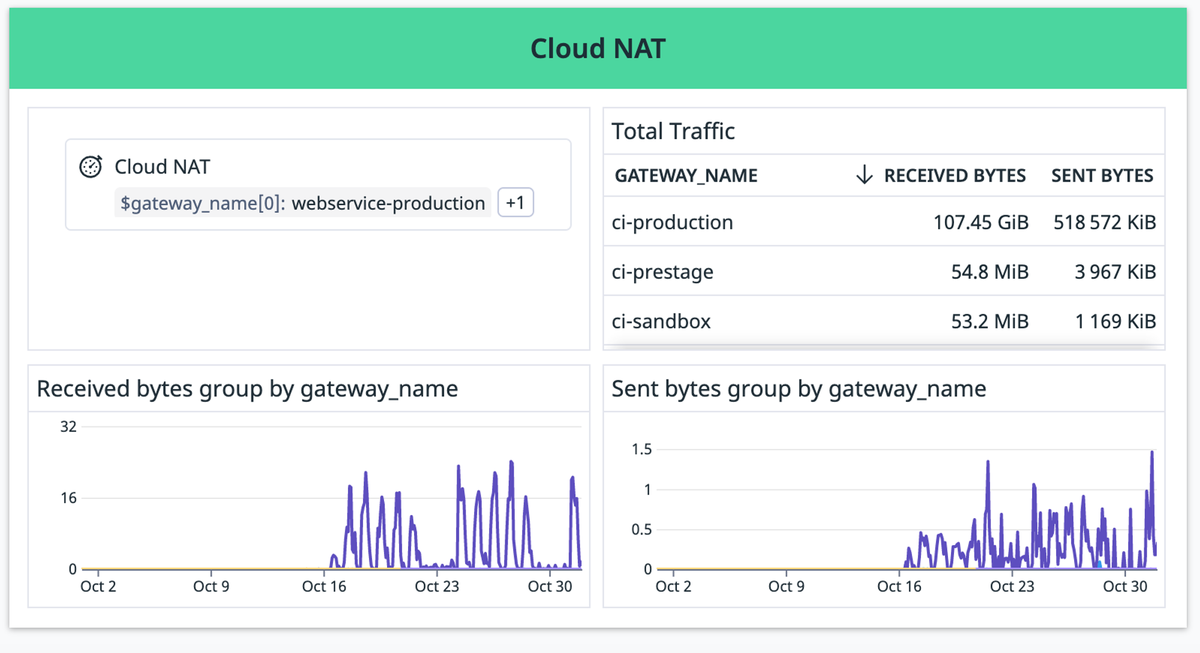
Billingで請求されてる転送量とDatadogで出ている転送量に大きな差異出ていました。DatadogのGCP Integration *4 はGCPのCloud Monitoing APIを数分おきにしか実行しない仕様なので、おそらくこのために差異が出ている可能性が高いです。
とはいえこのgatewayごとの転送量の割合自体は信用できそうです。
おそらくなのですが、GitLab CIがdockerイメージをpullする時の転送量がそのまま課金されている模様です...(つらい)
移行前にEC2のスポットインスタンスでGitLab CIを動かしていた時はパブリックサブネットで動かしていたためこの問題は踏まなかったようです。
そのためDependency ProxyでDockerイメージをGCSでキャッシュしてなるべくNATを通らないようにしました。
https://docs.gitlab.com/ee/user/packages/dependency_proxy/
おまけ:移行後の面白メトリクス
GitLab全体のトラフィック
GitLabで使ってるロードバランサーのトラフィックを可視化しました。
下記は10月分のメトリクスです。(10/16に移行したので実質半月分です)
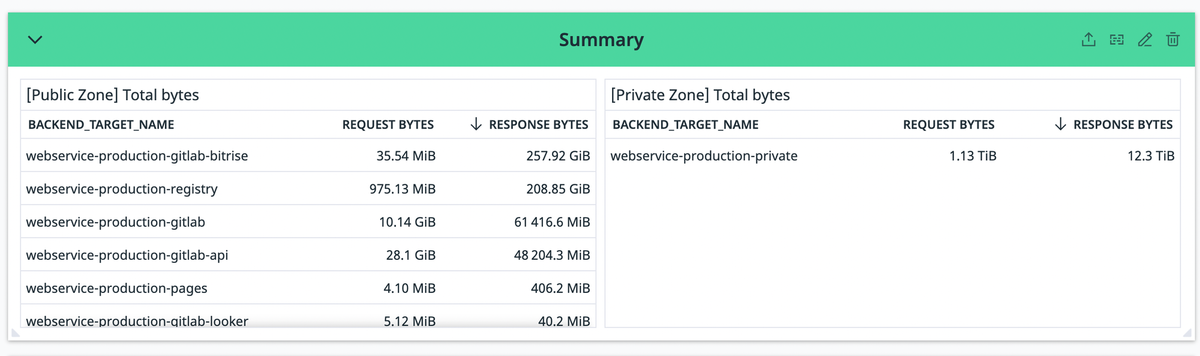
左側が全体公開ゾーン(インターネットからアクセスされる)で右側が限定公開ゾーン(CI内での通信)なんですが、CI内のDatadogで計測できてる部分だけでgit cloneだけで12TiBくらい通信されています。(前述のCloud Monitoing APIの実行間隔の仕様も加味すると実際はこの10倍くらいの転送量は発生してると思う)
移行前はこれがNAT Gateway経由でインターネットに出ていたのですが移行後は全部GCP内の通信になっています。
GitLab本体とRunnerの間の通信の転送料金がほとんど発生しなくなったのはいいのですが、その分の費用がCloud NATに移動したので若干複雑な気分です...
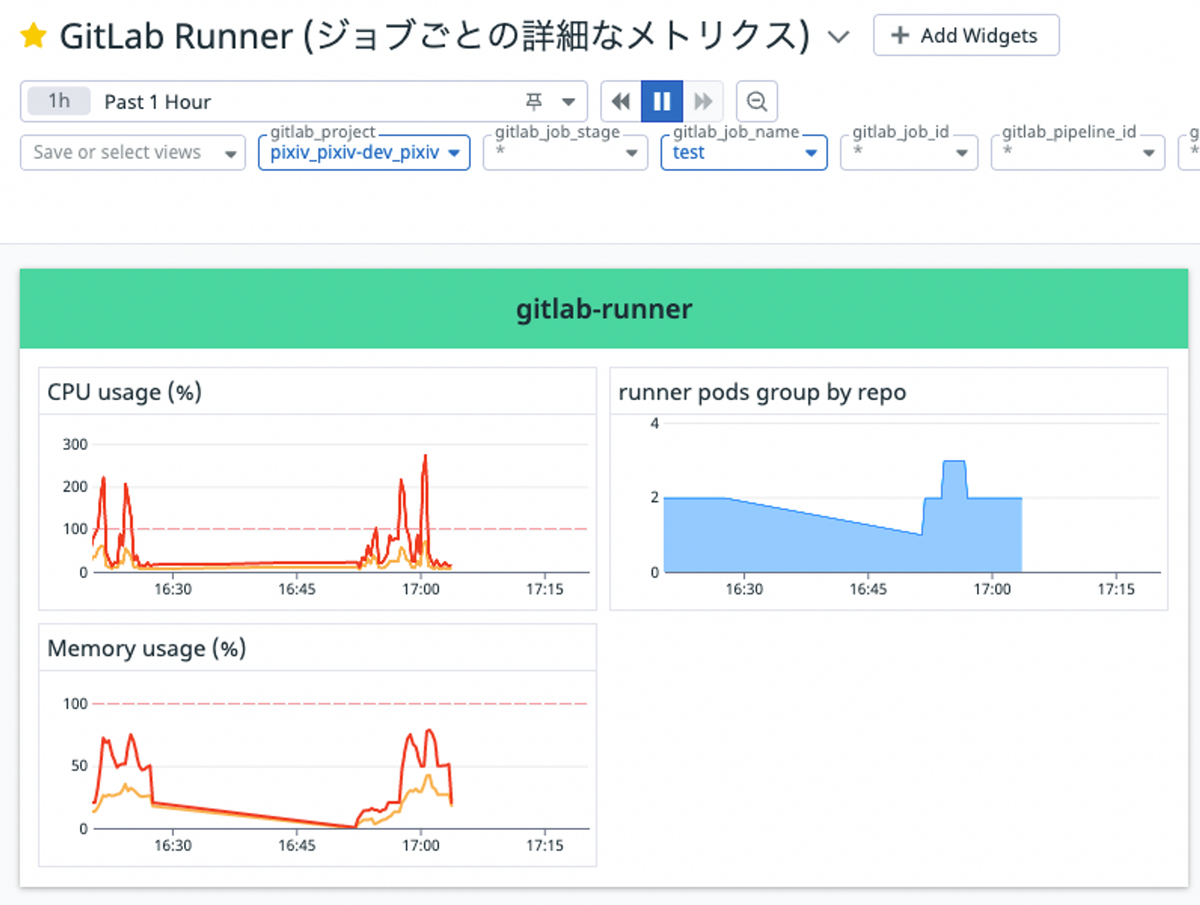
リポジトリ毎のCIの実行状況
GitLab RunnerのKubernetes executorではジョブ毎にpodが作られます。
GitLab Runnerの /etc/gitlab-runner/config.toml (Helm chartだとvaluesの runners.config )に下記のような設定を入れることで、GitLab CI実行時の環境変数をpodのラベルに付与することができます。
[runners.kubernetes.pod_labels]
gitlab_project = "${CI_PROJECT_PATH}"
gitlab_user = "${GITLAB_USER_LOGIN}"
gitlab_job_id = "${CI_JOB_ID}"
gitlab_job_name = "${CI_JOB_NAME}"
gitlab_job_stage = "${CI_JOB_STAGE}"
gitlab_pipeline_id = "${CI_PIPELINE_ID}"
またDatadogのHelm chartの values.yml で
datadog: podLabelsAsTags: gitlab_project: gitlab_project gitlab_user: gitlab_user gitlab_job_id: gitlab_job_id gitlab_job_name: gitlab_job_name gitlab_job_stage: gitlab_job_stage gitlab_pipeline_id: gitlab_pipeline_id
のようにpodのラベルをDatadogにタグとして送信するようにするとDatadogでメトリクスを見る時に絞り込むことができます。
これによりGitLabのリポジトリ単位でpodがいくつ作られているか(≒リポジトリ毎のCIの実行状況)をDatadogでいい感じに可視化できるようになりました。
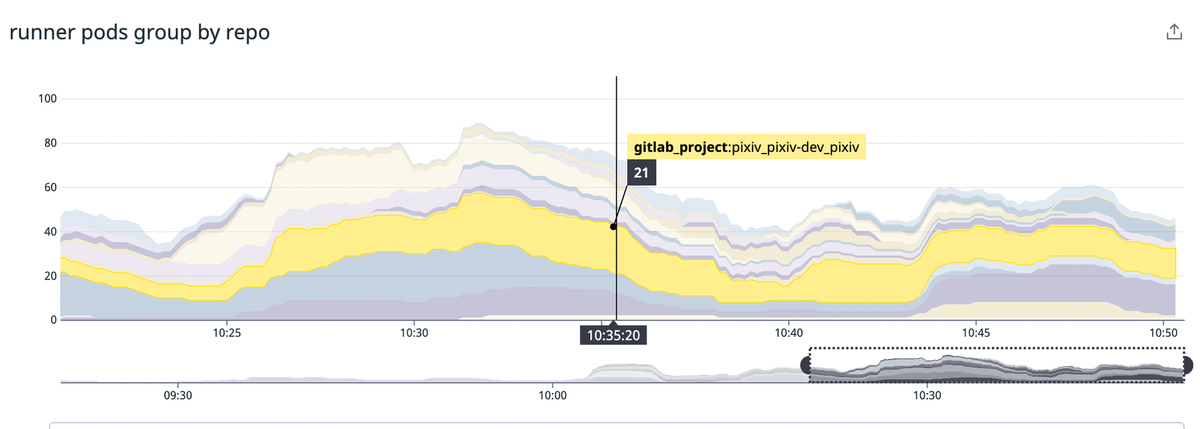
リポジトリ名のスラッシュはラベルに付与される時にアンダースコアに変換される仕様のようなので、pixiv/pixiv-dev/pixiv というリポジトリだとDatadogでは pixiv_pixiv-dev_pixiv
のように表示されます。
また、ジョブCIなども送信しているので特定のジョブでどれくらいのCPUやメモリを使っていたのかも簡単に見れるようになり、CIのパフォーマンスチューニングでも役に立つようになりました。
所感
GCP移行してよくなったこと
- 複数あったGitLabのログイン方法(StandardログインとLDAPログイン)を統一できた
- 業務形態によってはGitLabをcloneするのにVPNが必要だったが移行後はそれが不要になった
- Cloud IAP利用時の通信のオーバーヘッドがなくなって体感的にも早くなった
- GitLab本体とGitLab CI間の通信がインターネットを通らない内部通信になったので巨大なリポジトリでのCIが安定した
- 3.7GBくらいあるリポジトリだと50回に1回は
git cloneに失敗してたが、移行後は1回も失敗しなくなった
- 3.7GBくらいあるリポジトリだと50回に1回は
- 別のGCPプロジェクトにあるGKEのArgoCDからVPC ネットワーク ピアリングを使って限定公開ゾーン経由で直接GitLabに接続できるようになった
- 今まではCloud IAPがあったのでGitLabに直接接続することができず、Cloud Source Repositoriesを経由していた
GCP移行して悪くなったこと
- ssh周りのセットアップが少しややこしくなった
- 共用の開発サーバ上で開発する時に手元の秘密鍵をどこまでforwardしたらいいのか分かりづらい
- Cloud IAPのTunneling SSH Connectionsで踏み台サーバに接続しつつ、さらに踏み台サーバ経由で
git fetchすると少し遅い - ビジュアルリグレッションテストでBrowserStackを使った時に、Kubernetes executorで実行するとなぜかローカルよりも遅くなることがある
- 移行前後でRunnerのスペックは変えていない
- Kubernetesじゃない普通のDocker executorだと問題ないので謎
最後に
構築にあたってGCPのサポートの人には何回か質問させてもらいました。ありがとうございました!
*1:https://inside.pixiv.blog/edvakf/3457
*2:https://github.com/capistrano/capistrano
*3:https://gitlab.com/gitlab-org/omnibus-gitlab/-/blob/99975de6c8359c0dfd65eb741db8a03b1d3c0dca/docker/assets/sshd_config#L9
*4:https://docs.datadoghq.com/ja/integrations/google_cloud_platform/



