

「pixivコミック・ノベル」チームのエンジニアの pawa です。
pixivコミックはWebやアプリで漫画を試し読みできるサービスです。私が一番好きな pixivコミック作品は「温泉卓球☆コンパニオンズ!」です。
2017年7月4日、pixivコミック(Web版)の作品ページにタグ機能が追加されました。

これらのタグは、作品説明文から自動的に抽出されたもので、コンピュータに計算させた「作品のキーワードとして妥当な順番」に並んでいます。
今回は、このタグ機能が生まれるまでの物語をご紹介します。
問題提起
pixivコミックに携わる者として、以前から、次の2点を問題だと感じていました。
- 特定のジャンル(たとえばスポーツ)の漫画を探すのが難しい
- 「あわせて読みたい」作品がなぜ「あわせて読みたい」のか分かりにくい
私は、社会人になってから、大好きなスポーツが共通する人とスポーツをすることの果てしない楽しさというのを知りました。最近、卓球が大好きな娘が主人公の『灼熱の卓球娘』という作品を観て、漫画やアニメでもこの楽しい感覚を疑似体験できるということを知りました。
そこで、ふと「pixivコミックでもスポーツものを読んでみたい」と思って探してみました。しかし、pixivコミックには「スポーツ」カテゴリはなく、検索機能を使っても、作品タイトルに「野球」や「卓球」などの競技名が入っていないと探すのが困難な状態でした。運良くスポーツものを探し出しても、その作品に近いものを探そうと思うときにあるのが、「あわせて読みたい」というコンピュータがおすすめしてくれる機能しかありませんでした。
ユーザーの明確な欲求に沿って、能動的に、似た作品を回遊できるようにしたい。そこで出たアイディアが、作品説明文からキーワードを抽出して作品群をキーワードで結びつける(これを「タグ」と呼ぶ)という方法でした。
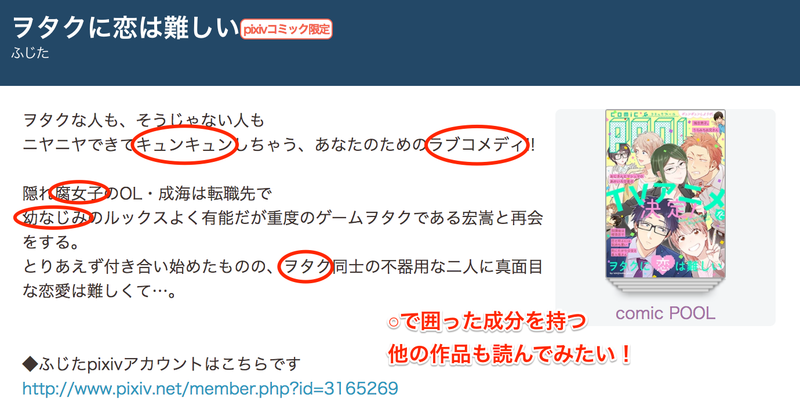
人気作品『ヲタクに恋は難しい』を例に挙げるなら、「キュンキュン」「ラブコメディ」「腐女子」「OL」「幼なじみ」「ヲタク」などのキーワードで似た作品を探せるイメージです。
解決手法
作品説明文の全文検索でも解決できますが、私自身が文章からのキーワード抽出を学生の時からやっていたこともあり、以下の理由で「自動タグ付け」による解決を目指しました。
- 全文検索エンジンを導入するのは大掛かり
- 作品の成分表示のようなことができるタグのほうが面白そう
- 読者がキーワードを入力しなくても、作品にタグ付けされたキーワードをタップするだけで回遊できる
大まかな手順としては以下のようになると考えました。
- 全作品の説明文を形態素解析器にかけて名詞(うまくいきそうなら副詞や形容詞も)を抽出
- BM25という情報検索で使われるアルゴリズムでキーワードを重み付けする
- 他の作品と結び付かないキーワードは捨てる
- BM25重み付けの値の高い順に上位
N個のキーワードを並べてやる(これを作品の「タグ」とする)
形態素解析器というのは、テキストを形態素(「意味を有する最小の言語単位。意味の最小のまとまりに相当する語形。 」『スーパー大辞林』より)に分割して、品詞などの情報を付与してくれるソフトウェアのことです。
形態素解析器の選定
形態素解析器としては「JUMAN++」「KyTea」「MeCab」などがあります。今回は、新語や固有表現に強い「mecab-ipadic-NEologd」があり、かつ、処理速度に優れる「MeCab」を使いました。
「mecab-ipadic-NEologd」の詳細は「新語・固有表現に強い『mecab-ipadic-NEologd』の効果を調べてみた : LINE Engineering Blog」をご覧ください。
この「mecab-ipadic-NEologd」を使うと、キーワードの元となる単語を適切に抽出することができます。その例として、『サイボーグクロちゃん』という作品の説明文では、「mecab-ipadic-NEologd」を使わなければ以下のように「コミック」「ボンボン」と単語分割されてしまうところを、「コミックボンボン」と適切に単語抽出してくれるようになります。

事前調査
実際に利用するテキストの傾向が分からないと解決手法が適用可能か判断ができません。そのため、事前にテキストデータの簡単な統計を調査しました。
作品説明文の簡単な統計
Rubyの「daru」というライブラリで「箱ひげ図」が描けるだけの統計データを出してみると以下の通りでした。
- 作品数:3248
- 平均:164字
- 最短:0字
- 25%タイル値:101字
- 中央値:144字
- 75%タイル値:198字
- 最長:1411字
Pythonの「Matplotlib」でヒストグラムを描くと以下の通りです。
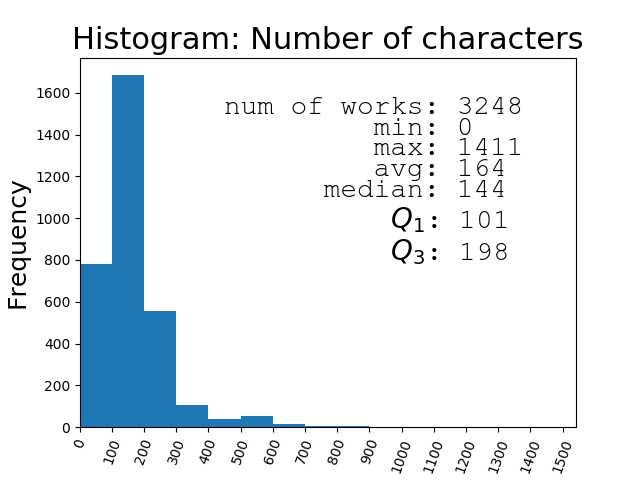
後の調査で39作品は作品説明文がないことが分かりました。
75%タイル値(Q3)と25%タイル値(Q1)から、3248作品中の半分程度の作品の説明文が100〜200字の範囲に収まるということが分かります。この短さで「作品のキーワードとしての妥当な順番」に並べ替えてタグにするというのは本当に可能なのでしょうか!?
Document Frequency
次に調査したのは Document Frequency でした。これは、ある単語が何文書に含まれるかという情報です。今回は作品説明文を1文書と見なすことにしました。
Document Frequency を調査した結果は以下の通りでした。
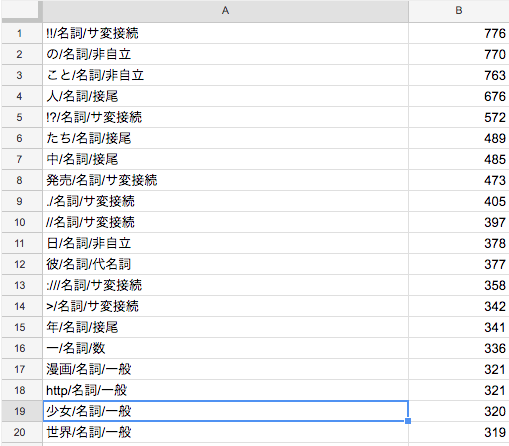
これは、「!!/名詞/サ変接続」が776文書(作品説明文)に出現して「の/名詞/非自立」が770文書に出現して……というデータになっています。この調査結果から、「!!/名詞/サ変接続」・「//名詞/サ変接続」・「たち/名詞/接尾」などの作品のタグとして不適切なものをフィルタリングする処理が必要だと判明しました。
フィルタリングルールは以下のように設定してコーディングしました。(細かいフィルタリングルールは一部省略)
- ひらがな・カタカナ・英語のアルファベットで1文字は除外
- 名詞の品詞細分類で「非自立」「接尾」「代名詞」は除外
- 名詞の品詞細分類で「数」かつ3桁未満は除外
- 副詞のホワイトリストを人手で作成
- 形容詞の「非自立」と「接尾」は除外
- 形容詞のブラックリストを人手で作成
- URLのような文字列を削除
- ストップワード(品詞などに関わらず無視する単語)の設定
- 形容詞で「い, ぃ, イ, ィ」のいずれかで終わっていないものは除外
このフィルタリング処理に加え、さらに、「解析前に行うことが望ましい文字列の正規化処理」という「mecab-ipadic-NEologd」の Wiki に書いてある処理も施し、「mecab-ipadic-NEologd」を使って Document Frequency を出し直した結果がこちらです。
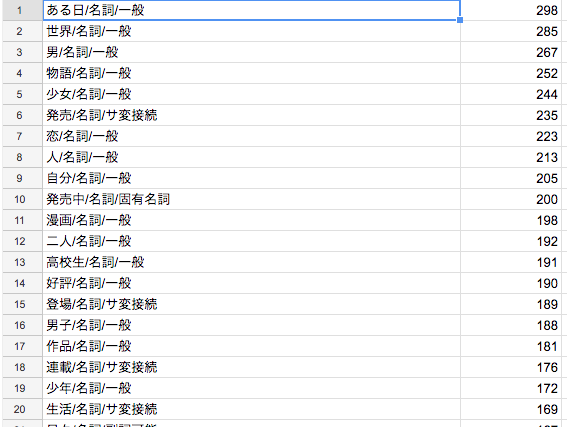
何やらいい具合にキーワード抽出できそうな下地が出来つつあるのを感じました。
下位の Document Frequency も問題がないか気になって見てみると以下のようになっていました。
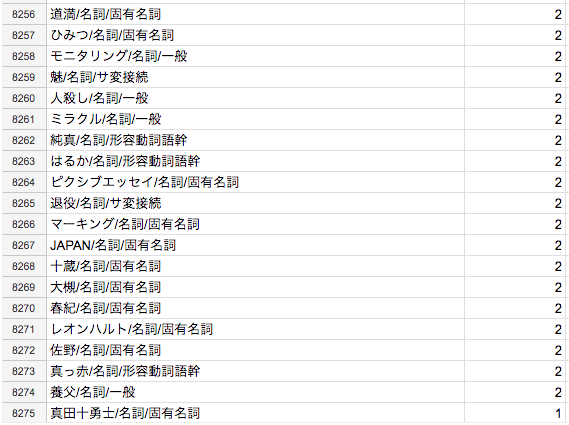
タグになっても問題なさそうですね。
特徴語(キーワード)抽出
特徴語抽出といえば TF-IDFですが、1作品につき複数文書からキーワードを抽出することも視野に入れていたため、BM25という文書長の異なる複数文書でもうまく対処できるアルゴリズムで特徴語を抽出しました。BM25はクエリ集合に対する文書の関連性を計算するランキング関数なのでこのままでは使えません。今回は文書集合Dに対する単語の関連性を計算する関数に変形して利用しました。アルゴリズムは以下の通りです。
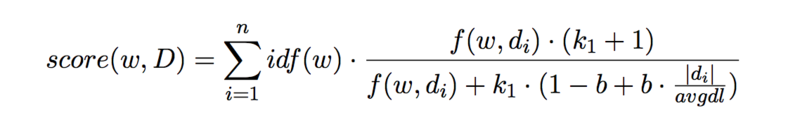
D:{d1, d2, … dn}(文書集合)w:文書集合内に含まれる任意の単語idf:log( (文書数) / Document Frequency )(逆文書頻度)f(w, di):文書diにおけるwの Term Frequency (出現頻度回数)avgdl:Dの長さの平均|di|:文書diの長さ(字数)k1,b:チューニングパラメータ(よく使われるk1 = 2.0, b = 0.75に指定)
文書数「1」(1作品につき1作品説明文)で計算してみた結果、以下のスプレッドシートの通りになりました。(左から「作品ID」「作者名」「作品名」「タグ/品詞/品詞細分類 BM25スコア」の順で並んでいます。)BM25のスコアが高いほど作品のタグとして適しているものが出るようになってほしいため、タグはBM25スコアの降順に並んでいます。
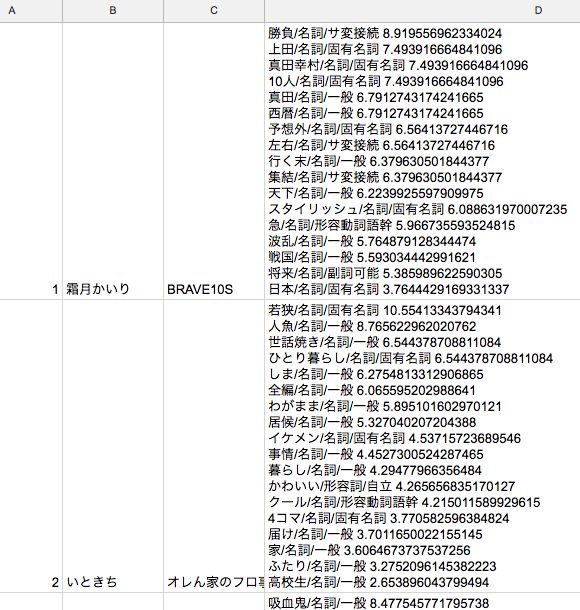
精度不足とその対策
この結果を眺めて「勝負」のようなありふれた単語のスコアが高いのを発見しました。どうも一般語フィルターとして機能するべき IDF(逆文書頻度)が機能していないようです。これは作品説明文が短すぎることに起因していると考えました。
ここで私は青空文庫の耕作員(青空文庫の作品の入力や校正に携わるボランティアの方々)の力を借りることにしました。一般語フィルターとして使うには現代の言葉でつづられている「日本語Wikipedia」のデータのほうが適しているのですが、小説のほうが私にとっては「心ときめきするもの」なので青空文庫のデータを一般語フィルターとして使うことにしました。
青空文庫のデータはPerlでダウンロードしてデータベース(SQLite3)に保存した後、NDC(日本十進分類法)が 913(日本文学の小説・物語を示す分類番号)で新字新仮名(旧字だと形態素解析誤りが起こるため)の作品のデータを抽出して使いました。このデータの文書長の統計情報は以下の通りでした。
- 作品数:2616
- 平均:29704字
- 最短:519字
- 25%タイル値:7861字
- 中央値:13893字
- 75%タイル値:24446字
- 最長:884492字
これだけの字数があれば一般語フィルターとしても機能しそうです。このデータからaozora_idf = log(N/df(w))を算出して元のidfに乗算してやると、一般的な単語や pixivコミック説明文中で頻出の単語のスコアは下降して、一般的でない単語や pixivコミック内でも珍しい単語のスコアが上昇するという、もっともいい具合になりました。
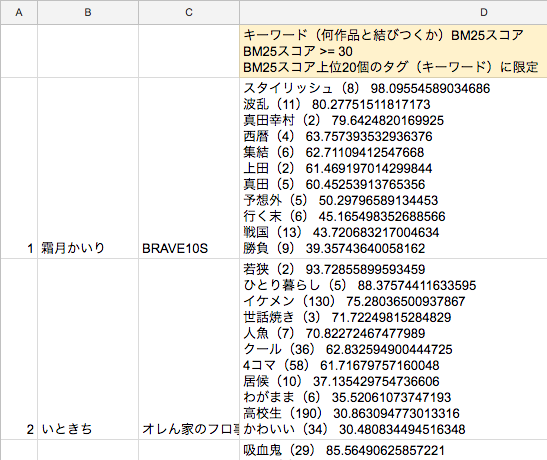
青空文庫のデータも利用して出した結果が以下のスプレッドシートです。「スタイリッシュ」「ひとり暮らし」「イケメン」などの青空文庫で珍しい単語の順位が上がり、「勝負」「上田」などの青空文庫でありふれた単語の順位が下がっています。
プロトタイプ
これらのデータを用いて全作品をタグ付けして、社内のみアクセス可能な環境にアップロードしてみました。試しに「メイド」タグで検索してみると、メイドさんがいっぱい出てきました!

社内レビューの後、無事に本番リリースのGOサインが出ました。
本番リリース
出版社さんの確認作業の後、2017年7月4日に無事にタグ機能をリリースできました。セキュリティ上の理由で「mecab-ipadic-NEologd」による MeCab の辞書の自動更新は実現できませんでしたが、作品のタグ付けは完全に自動化できました。
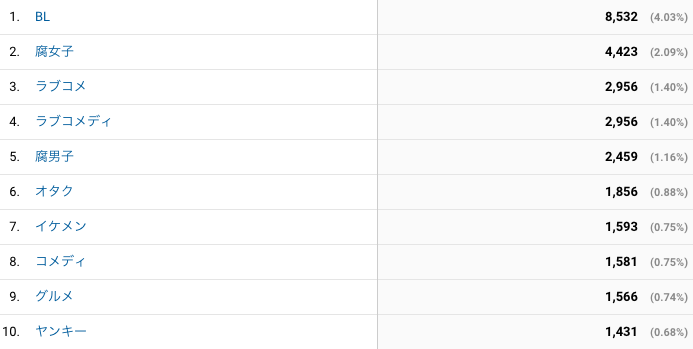
どういうタグがクリックされているか気になって見てみると、以下のように満遍なくクリックされていました。
最後に
このタグ付けデータを生かすのはまだまだこれからです。
- タグのクリック数ランキング
- あるタグに関連する別のタグに容易にアクセスできる機能
なども考えています!
普段は表側に出てこない機能を作ることが多いのですが、今回は久しぶりに表側に出てきて、かつ、将来も残り続ける新機能を追加できて良かったです。
エンジニア募集中
ピクシブ株式会社ではユーザー視点で新機能を開発できるエンジニアを募集中です!



