

はじめましての方ははじめまして。新卒期間も終了し、晴れて一般エンジニアになりました Javakky です。 今回は、 Scala の Linter であり自動リファクタリングツールでもある Scalafix について、ルール開発の流れについて話していこうと思います。
Scalafix とは?
Scalafix は Scala の Linter として有名なツールの一つです。
このツールの大きな特徴として、発見した修正箇所を自動で書き換えることができる。というものになっています。
イメージとしては、 IntelliJ のコードインスペクションのクイックフィックスを利用するような感じです。
もう一つの特徴として、 SyntacticRule, SemanticRule の2種類のルールの作り方が存在することが挙げられます。
SyntacticRule
まず、 SyntacticRule はいわゆるフォーマッタなどと同じような作りになっていて、対象のコードを字句解析した後に得られる文字列配列を操作することで校正や書き換えを行うことができるようになっています。
擬似コードとして val x = 3 というコードから得られるトークンを以下に示します。
[ Token$KwVal("val"), Token$Space(" "), Token$Ident("x"), Token$Space(" "), Token$Equals("="), Token$Space(" "), Token$Constant$Int("3") ]
詳細は後述しますが、自作のルールでは不要なセミコロンの削除のために SyntacticRule を利用しました。
SyntacticRule の強みとして、コードの構文木の生成や型情報の取得といった重たい処理を挟まないため、高速に動作させることができるというものがあります。
SemanticRule
二つ目が SemanticRule です。こちらは実際にコードを構文解析し、その結果得られる木を操作しながら校正を行います。
例えば、 val x = 3 というコードを collect で操作すると、以下のような順番で値がヒットします。
※疑似コードです。実際にはリストではないのですが、わかりやすさのためにそのように表記しています。
[ Source("val x = 3"), Defn$Val("val x = 3"), Pat$Var("x"), Term$Name("x"), Lit$Int("3") ]
下図のように、 Tree を継承した複数のインターフェースやクラスが定義されていて、それぞれのインスタンスが入れ子になっています。
例えば Lit にマッチさせることで、あらゆるリテラル表記にマッチさせることができたりします。
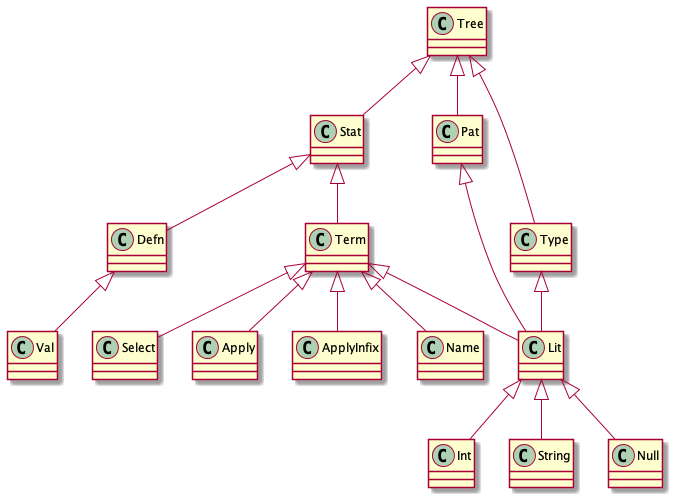
次にこの中の Defn$Val の定義を見てみましょう。
pats には左辺の変数一覧が、 rhs には右辺の式が格納されていて、一度 Defn$Val でマッチさせてから中身を参照することもできるようになっています。
class Val( mods: List[Mod], pats: List[Pat] @nonEmpty, decltpe: Option[scala.meta.Type], rhs: Term ) extends Defn
Treeの各クラスの定義は、 Tree.scala から見ることができます。
Patch
作成する各ルールは、 Patch と呼ばれる書き換え内容を表現するクラスのインスタンスを返すことで書き換え (または Lint) を行うことができます。
Patch には以下のようなメソッドが存在し、その返り値を返却することでルールを実装していきます。
Patch.scala:
empty: 何も書き換えを行わないreplaceToken(token: Token, toReplace: String): トークンのあった位置を文字列で置換するaddAround(tok: Token, left: String, right: String): トークンの左右に文字列を追加するlint(msg: Diagnostic): コードには変更を加えずに警告を出力する
Scalafixのカスタムルールの開発
チュートリアルのセットアップページ にある通り、 sbt new scalacenter/scalafix.g8 コマンドを用いて sbt プロジェクトを作成します。
build.sbt の inThisBuild \ organization では後述する Maven Central Repository で取得したネームスペースを設定しましょう。
またサブプロジェクトの rules の settings にモジュール名 (と後で削除しますがバージョン) も設定するとよいでしょう。
lazy val rules = projectMatrix
.settings(
moduleName := ${ルール名},
version := “0.0.1-SNAPSHOT”
libraryDependencies ++= Seq(
"ch.epfl.scala" %% "scalafix-core" % V.scalafixVersion
)
)
.defaultAxes(VirtualAxis.jvm)
.jvmPlatform(rulesCrossVersions)
今回、私たちが作成したルールの完全な設定は こちら にあります。ご参考までにどうぞ。
Scalafix
もちろんこのリポジトリにも Scalafix を導入してコードの品質管理をしたいですよね!
しかし、Scalafix は projectMatrix に対応していなさそうだったため、 rules と同じディレクトリを指すサブプロジェクトを作成しました。
sbt “src/scalafixAll” で Scalafix が利用できます。
lazy val src = (project in file("rules"))
.settings(
libraryDependencies ++= Seq(
"ch.epfl.scala" %% "scalafix-core" % V.scalafixVersion
),
scalacOptions ++= Seq(
"-deprecation",
"-feature",
"-Ywarn-unused:imports,locals,patvars"
),
semanticdbEnabled := true,
semanticdbVersion := scalafixSemanticdb.revision,
publish / skip := true
)
Scala Test
ルールを実装する中で、汎用的な処理を持つクラスを作成する必要が出てきました。このクラスをテストするため、 ScalaTest を導入しました。
導入方法としては rules, src サブプロジェクトの Dependencies に追加するだけです。
libraryDependencies += "org.scalatest" %% "scalatest" % "3.2.11" % "test"
また、テストコードについては rules/src/test/scala 以下に設置します。
これで、 sbt test を実行した際に src/test にあるテストコードを実行してくれるようになります。
sbt-license-report
このルールをOSSとして公開することに決めたので、依存関係を全て NOTICE.md に吐き出したくなりました。
こんな時には sbt-license-report が役に立ちます。
設定は plugins.sbt ファイルに以下の行を追加して、
addSbtPlugin("com.typesafe.sbt" % "sbt-license-report" % "1.2.0")
src サブプロジェクトに以下の設定を追加するだけで完了します!
# 出力するファイルの名前 licenseReportTitle := "NOTICE", # 出力するディレクトリ licenseReportDir := `<プロジェクト名>`.base, # 形式 (Markdown, Html, Csv) licenseReportTypes := Seq(MarkDown)
sbt "src/dumpLicenseReport" コマンドで NOTICE.md はあなたのものです。
公開前には LICENCE ファイルを手動で追加することも忘れないようにしましょう。
sbt-ci-release
作成したルールを公開するにあたって、毎回手動で publish するのも面倒だな〜と思う方は多いのではないでしょうか?
sbt-ci-release の README 通りに GitHub Actions と plugins.sbt の設定をするだけで、git のタグを打つのに反応して自動でリリース作業を行ってくれるようになります。
ローカルでの実行
いくらテストを書いたとはいえ、 Scalafix のルールをリリースする前に別のリポジトリで動作を試したい!なんてことはありませんか?
そんな時は publishLocal コマンドがおすすめです。Scalafix ルール側のリポジトリで sbt publishLocal を行うと、 jar ファイルが ~/.ivy2/local/ に保存され、まるで Maven Central Repository にあるかのように利用することができます。デプロイ前の動作確認にぜひご利用ください。
作成したルール
UnnecessarySemicolon
こちらは行末の不要なセミコロンを削除するルールです。 このルールでは、 (技術的には可能ですが) 連続する処理の中間に記述されているセミコロンは分割していません。
UnnecessarySemicolon は SyntacticRule として実装されていて、トークンを collect で走査した後、; にマッチし、かつ、直後が行末である場合にヒットするように実装されています。
class UnnecessarySemicolon extends SyntacticRule("UnnecessarySemicolon") { override def fix(implicit doc: SyntacticDocument): Patch = { doc.tokens.zipWithIndex.collect { case (semicolon: Token.Semicolon, i) => doc.tokens(i + 1) match { case _ @(Token.CR() | Token.LF() | Token.EOF()) => Patch.replaceToken(semicolon, "") case _ => Patch.empty } }.asPatch } }
ZeroIndexToHead
これはあるシンボルに対して (0) を適用している場合に head というメソッドの呼び出しに置換するルールです。
ここでは Term$Apply (関数適用) の構文にマッチした場合に、() の中身がリテラルの 0 だったら .head 呼び出しに置き換える。という処理を行っています。
Patch#replaceTree の第二引数は文字列なため、一旦 head メソッド呼び出し (Select) の Tree を一旦組んでから toString した結果を渡すことで変換後の文字列を生成しています。
class ZeroIndexToHead extends SemanticRule("ZeroIndexToHead") { override def fix(implicit doc: SemanticDocument): Patch = { doc.tree.collect { case t @ Term.Apply(x1, List(Lit.Int(0))) => Patch.replaceTree( t, Term.Select(x1, Term.Name("head")).toString ) }.asPatch } }
しかし、これでは x1(0) が本当に x1.head に置換しても問題ない確証が持てません。なので、 x1 が想定される型 (ここでは、 Seq かつ IndexedSeq ではないクラス) かどうかをチェックしたいと思います。
Scalafix でシンボルの型を取り出す
今回は Symbol が表す文字列から完全修飾クラス名を類推するというアプローチをとりました。 SemanticType を Class[_] に変換できるようにする #6 Scalafix の SemanticRule では、裏で SemanticDB という Scala コードの構文情報を生成するライブラリを利用しています。
ここで、 Scala の Symbol は以下のように表されます
1. Package : 各記号名を / で連結する
2. Class または Trait : パッケージ名 + シンボル名 + #
3. Object : パッケージ名 + シンボル名 + .
4. Type: 所有者名 + シンボル名 + #
まず、 2. のパターンでは、完全修飾クラス名に変換することが容易なため、リフレクションによって Class[_] に変換を行います。
Class.forName(str.replace('/', '.').init)
ここで、 3. のパターンを考えると単純な末尾切り落としではなく、判定を行うべきです。
しかし、(少なくとも私たちのリポジトリで) 3. が返されるパターンは apply 呼び出しの左項であることがほとんどでした。そこで、 3. のパターンではまず対象のオブジェクトがコンパニオンオブジェクト、かつ、シンボルが apply 呼び出しであると仮定して変換を行うことにしました。これであれば、 init のままで問題ありません。
これで多くの型を Class[_] に変換することができました。しかし、少し厄介な問題があります。それは、 Java 標準APIにあるクラスが指定されている場合です。
例えば、 java.lang.String が使われている場合、 scala.Predef オブジェクトに定義された type としてシンボルが返されてしまいます。
そこで、上記コードで変換に失敗した場合には、あるオブジェクト内で再定義された type であると仮定してより高度なリフレクションにより型を取得することにしました。
val str = str.replace('/', '.').init val lastDot = str.lastIndexOf('.') // 最後の `.` までの文字列をオブジェクトに変換する val objCls = Class.forName(str.take(lastDot) + "$") import scala.reflect.runtime.universe.{TypeName, runtimeMirror} val mirror = runtimeMirror(getClass.getClassLoader) // 前項で生成したオブジェクトから `type` を取り出す mirror.runtimeClass(mirror.classSymbol(objCls).toType.decl( TypeName(str.drop(lastDot + 1)) ).typeSignature.dealias.typeSymbol.asClass)
CheckIsEmpty
こちらは Seq (Scala にあるリストのような構造) の空チェックに .isEmpty を利用するように書き換えを行うルールです。
そして以下が fixメソッドのすべてです。ここでは具体的にどういうパターンがヒットするかは記載されていません。
class CheckIsEmpty extends SemanticRule("CheckIsEmpty") { override def fix(implicit doc: SemanticDocument): Patch = { doc.tree.collect { // IsDefined かつ書き換えが必要なパターンであれば case t @ IsDefined(x1, rewrite) if rewrite && isType(x1, classOf[Option[Any]]) => Patch.replaceTree(t, Term.Select(x1, Term.Name("isDefined")).toString()) // NonEmpty かつ書き換えが必要なパターンであれば case t @ NonEmpty(x1, rewrite) if rewrite && CheckIsEmpty.isTypeHasIsEmpty(x1) => Patch.replaceTree(t, Term.Select(x1, Term.Name("nonEmpty")).toString()) // IsEmpty かつ書き換えが必要なパターンであれば case t @ IsEmpty(x1, rewrite) if rewrite && CheckIsEmpty.isTypeHasIsEmpty(x1) => Patch.replaceTree(t, Term.Select(x1, Term.Name("isEmpty")).toString()) }.asPatch } }
このように Scalafix のルール作成では 抽出子 を利用することでルールをシンプルに記述することができます。 抽出子はパターンマッチ時にインスタンスを複数の別のインスタンスに変換することができるため、複数のパターンをまとめて扱うことができるのです。
では実際に、 IsEmpty オブジェクトの実装を見てみましょう。
unapply メソッドを定義し、受け取った Tree インスタンスをマッチさせることで、 .isEmpty を呼び出すべき Term を返却しています。また、 !seq.IsEmpty のように否定が連続しているものを変換するため、同時に直接変換すべき項であるかの情報も返しています。
private object IsEmpty { def unapply(tree: Tree)(implicit doc: SemanticDocument): Option[(Term, Boolean)] = { tree match { // `seq.isEmpty` は変換不要だが IsEmpty ではある case _ @Term.Select(x1: Term, _ @Term.Name("isEmpty")) => Some(x1, false) // `seq.size == 0` case _ @Term.ApplyInfix( Term.Select(x1: Term, _ @(Term.Name("size") | Term.Name("length"))), Term.Name("=="), Nil, List(Lit.Int(0)) ) => Some((x1, true)) case _ @Term.ApplyUnary(Term.Name("!"), NonEmpty(x1, _)) => Some((x1, true)) case _ @Term.ApplyUnary(Term.Name("!"), IsDefined(x1, _)) => Some((x1, true)) // option == None case _ @Term.ApplyInfix(x1: Term, _ @Term.Name("=="), Nil, List(Term.Name("None"))) if isType(x1, classOf[Option[Any]]) => Some((x1, true)) // None == option case _ @Term.ApplyInfix(Term.Name("None"), _ @Term.Name("=="), Nil, List(x1: Term)) if isType(x1, classOf[Option[Any]]) => Some((x1, true)) case _ => None } } }
コンフィグの利用
CheckIsEmpty ルールを実装したところで、1つのアイデアが浮かびました。
実は Option の nonEmpty と isDefined は同じ処理を持つメソッドなので、そこも統一できると嬉しい!というものです。
しかし、IntelliJ などの変換規則ではこれは規定されていない書き換えルールのため、この好みが別れるルールだと考えました。そこで、 Option の nonEmpty を変換するかどうかは .scalafix.conf で設定ができるようにすることにしました。
今回はコードの例示を省略しますが、これはユーザーガイドの Tutorial にて解説があります。
Use withConfiguration to make a rule configurable
NonCaseException
このルールは弊社独自のコーディング規約に基づいたルールで、 Exception を継承した独自例外を case class として実装している場合にエラーを出すというものです。
もしこのルールを書き換えルールとして定義した場合、対象の Exception を生成している箇所全てを new を用いたインスタンス化に置き換える必要が出てしまいます。それでは工数がかかりすぎるため、以下のチュートリアルを参考に Lint ルールとして実装しました。
Use Diagnostic to report linter errors
今後の展望
実は先日行われた Scala Matsuri 2022 Day2 にて発表を行ったり、交流会でお話ししてきたりしました。 その中で、Scalafix によるリッチなルール作成について以下のようなご意見を頂きました。
- Semantic DB を生成する段階で情報が単純化されているので型情報を上手く扱うことが難しい (@tanishiking さんより)
- Scalafix の
SemanticRuleは非常に重いのであまり多用したくない - Wartremover を利用するのもそれはそれで課題がいくつかある
- TASTy を利用した Linter を作成する or 既存の Linter で TASTy を利用するといい感じかもしれない?
- しかし TASTy が利用できるのは Scala 3 以降のみ
- Scalafix で TASTy を利用するにはある程度大きく作り替える必要がありそう
上記を勘案した結果、ひとまずは scalafix-pixiv-rule の開発を続けつつ、 Scala 3 移行後に方針を再考していくことにしました。 ルールなども随時追加していく予定ですので、続報をお待ちください!



